预计阅读本页时间:-

4.3.3 目录的实现
在读文件前,必须先打开文件。打开文件时,操作系统利用用户给出的路径名找到相应目录项。目录项中提供了查找文件磁盘块所需要的信息。因系统而异,这些信息有可能是整个文件的磁盘地址(对于连续分配方案)、第一个块的编号(对于两种链表分配方案)或者是i节点号。无论怎样,目录系统的主要功能是把ASCII文件名映射成定位文件数据所需的信息。
与此密切相关的问题是在何处存放文件属性。每个文件系统维护诸如文件所有者以及创建时间等文件属性,它们必须存储在某个地方。一种显而易见的方法是把文件属性直接存放在目录项中。很多系统确实是这样实现的。这个办法用图4-14a说明。在这个简单设计中,目录中有一个固定大小的目录项列表,每个文件对应一项,其中包含一个(固定长度)文件名、一个文件属性结构以及用以说明磁盘块位置的一个或多个磁盘地址(至某个最大值)。
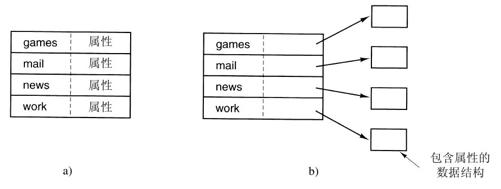
对于采用i节点的系统,还存在另一种方法,即把文件属性存放在i节点中而不是目录项中。在这种情形下,目录项会更短:只有文件名和i节点号。这种方法参见图4-14b。后面我们会看到,与把属性存放到目录项中相比,这种方法更好。图4-14中的两种处理方法分别对应Windows和UNIX,在后面我们将讨论它们。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
到目前为止,我们已经假设文件具有较短的、固定长度的名字。在MS-DOS中,文件有1~8个字符的基本名和1~3字符的可选扩展名。在UNIX V7中文件名有1~14个字符,包括任何扩展名。但是,几乎所有的现代操作系统都支持可变长度的长文件名。那么它们是如何实现的呢?
最简单的方法是给予文件名一个长度限制,典型值为255个字符,然后使用图4-14中的一种设计,并为每个文件名保留255个字符空间。这种处理很简单,但是浪费了大量的目录空间,因为只有很少的文件会有如此长的名字。从效率考虑,我们希望有其他的结构。
一种替代方案是放弃“所有目录项大小一样”的想法。这种方法中,每个目录项有一个固定部分,这个固定部分通常以目录项的长度开始,后面是固定格式的数据,通常包括所有者、创建时间、保护信息以及其他属性。这个固定长度的头的后面是实际文件名,可能是如图4-15a中的正序格式放置(如SPARC机器) [1] 。在这个例子中,有三个文件,project-budget、personnel和foo。每个文件名以一个特殊字符(通常是0)结束,在图4-15中用带叉的矩形表示。为了使每个目录项从字的边界开始,每个文件名被填充成整数个字,如图4-15中带阴影的矩形所示。
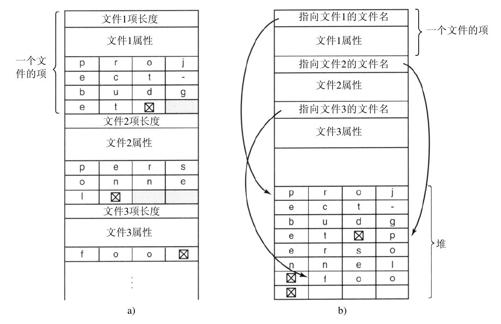
这个方法的缺点是,当移走文件后,就引入了一个长度可变的空隙,而下一个进来的文件不一定正好适合这个空隙。这个问题与我们已经看到的连续磁盘文件的问题是一样的,由于整个目录在内存中,所以只有对目录进行紧凑操作才可节省空间。另一个问题是,一个目录项可能会分布在多个页面上,在读取文件名时可能发生页面故障。
处理可变长度文件名字的另一种方法是,使目录项自身都有固定长度,而将文件名放置在目录后面的堆中,如图4-15b所示。这一方法的优点是,当一个文件目录项被移走后,另一个文件的目录项总是可以适合这个空隙。当然,必须要对堆进行管理,而在处理文件名时页面故障仍旧会发生。另一个小优点是文件名不再需要从字的边界开始,这样,原先在图4-15a中需要的填充字符,在图4-15b中的文件名之后就不再需要了。
到目前为止,在需要查找文件名时,所有的方案都是线性地从头到尾对目录进行搜索。对于非常长的目录,线性查找就太慢了。加快查找速度的一个方法是在每个目录中使用散列表。设表的大小为n。在输入文件名时,文件名被散列到1和n-1之间的一个值,例如,它被n除,并取余数。其他可以采用的方法有,对构成文件名的字求和,其结果被n除,或某些类似的方法。
不论哪种方法都要对与散列码相对应的散列表表项进行检查。如果该表项没有被使用,就将一个指向文件目录项的指针放入,文件目录项紧连在散列表后面。如果该表项被使用了,就构造一个链表,该链表的表头指针存放在该表项中,并链接所有具有相同散列值的文件目录项。
查找文件按照相同的过程进行。散列处理文件名,以便选择一个散列表项。检查链表头在该位置上的所有表项,查看要找的文件名是否存在。如果名字不在该链上,该文件就不在这个目录中。
使用散列表的优点是查找非常迅速。其缺点是需要复杂的管理。只有在预计系统中的目录经常会有成百上千个文件时,才把散列方案真正作为备用方案考虑。
一种完全不同的加快大型目录查找速度的方法是,将查找结果存入高速缓存。在开始查找之前,先查看文件名是否在高速缓存中。如果是,该文件可以立即定位。当然,只有在构成查找主体的文件非常少的时候,高速缓存的方案才有效果。










