预计阅读本页时间:-

4.4.2 文件系统备份
比起计算机的损坏,文件系统的破坏往往要糟糕得多。如果由于火灾、闪电电流或者一杯咖啡泼在键盘上而弄坏了计算机,确实让人伤透脑筋,而且又要花上一笔钱,但一般而言,更换非常方便。只要去计算机商店,便宜的个人计算机在短短一个小时之内就可以更换(当然,如果这发生在大学里面,则发出订单需3个委员会的同意,5个签字要花90天的时间)。
不管是硬件或软件的故障,如果计算机的文件系统被破坏了,恢复全部信息会是一件困难而又费时的工作,在很多情况下,是不可能的。对于那些丢失了程序、文档、客户文件、税收记录、数据库、市场计划或者其他数据的用户来说,这不啻为一次大的灾难。尽管文件系统无法防止设备和介质的物理损坏,但它至少应能保护信息。直接的办法是制作备份。但是备份并不如想象得那么简单。让我们开始考察。
许多人都认为不值得把时间和精力花在备份文件这件事上,直到某一天磁盘突然崩溃,他们才意识到事态的严重性。不过现在很多公司都意识到了数据的价值,常常把数据转到磁带上存储,并且每天至少做一次备份。现在磁带的容量大至几十甚至几百GB,而每个GB仅仅需要几美分。其实,做备份并不像人们说得那么烦琐,现在就让我们来看一下相关的要点。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
做磁带备份主要是要处理好两个潜在问题中的一个:
1)从意外的灾难中恢复。
2)从错误的操作中恢复。
第一个问题主要是由磁盘破裂、火灾、洪水等自然灾害引起的。事实上这些情形并不多见,所以许多人也就不以为然。这些人往往也是以同样的原因忽略了自家的火灾保险。
第二个原因主要是用户意外地删除了原本还需要的文件。这种情况发生得很频繁,使得Windows的设计者们针对“删除”命令专门设计了特殊目录——“回收站”,也就是说,在人们删除文件的时候,文件本身并不真正从磁盘上消失,而是被放置到这个特殊目录下,待以后需要的时候可以还原回去。文件备份更主要是指这种情况,这就允许几天之前,甚至几个星期之前的文件都能从原来备份的磁带上还原。
为文件做备份既耗时间又费空间,所以需要做得又快又好,这一点很重要。基于上述考虑我们来看看下面的问题。首先,是要备份整个文件系统还是仅备份一部分呢?在许多安装配置中,可执行程序(二进制代码)放置在文件系统树的受限制部分,所以如果这些文件能直接从厂商提供的CD-ROM盘上重新安装的话,也就没有必要为它们做备份。此外,多数系统都有专门的临时文件目录,这个目录也不需要备份。在UNIX系统中,所有的特殊文件(也就是I/O设备)都放置在/dev目录下,对这个目录做备份不仅没有必要而且还十分危险——因为一旦进行备份的程序试图读取其中的文件,备份程序就会永久挂起。简而言之,合理的做法是只备份特定目录及其下的全部文件,而不是备份整个文件系统。
其次,对前一次备份以来没有更改过的文件再做备份是一种浪费,因而产生了增量转储的思想。最简单的增量转储形式就是周期性地(每周一次或每月一次)做全面的转储(备份),而每天只对当天更改的数据做备份。稍微好一点的做法只备份自最近一次转储以来更改过的文件。当然了,这种做法极大地缩减了转储时间,但操作起来却更复杂,因为最近的全面转储先要全部恢复,随后按逆序进行增量转储。为了方便,人们往往使用更复杂的增量转储模式。
第三,既然待转储的往往是海量数据,那么在将其写入磁带之前对文件进行压缩就很有必要。可是对许多压缩算法而言,备份磁带上的单个坏点就能破坏解压缩算法,并导致整个文件甚至整个磁带无法阅读。所以是否要对备份文件流进行压缩必须慎重考虑。
第四,对活动文件系统做备份是很难的。因为在转储过程中添加、删除或修改文件和目录可能会导致文件系统的不一致性。不过,既然转储一次需要几个小时,那么在晚上大部分时间让文件系统脱机是很有必要的,虽然这种做法有时会令人难以接受。正因如此,人们修改了转储算法,记下文件系统的瞬时状态,即复制关键的数据结构,然后需要把将来对文件和目录所做的修改复制到块中,而不是处处更新它们(Hutchinson等人,1999)。这样,文件系统在抓取快照的时候就被有效地冻结了,留待以后空闲时再备份。
第五,即最后一个问题,做备份会给一个单位引入许多非技术性问题。如果当系统管理员下楼去取打印文件,而毫无防备地把备份磁带搁置在办公室里的时候,就是世界上最棒的在线保安系统也会失去作用。这时,一个间谍所要做的只是潜入办公室、将一个小磁带放入口袋,然后绅士般地离开。再见吧保安系统。即使每天都做备份,如果碰上一场大火烧光了计算机和所有的备份磁带,那做备份又有什么意义呢?由于这个原因,所以备份磁带应该远离现场存放,不过这又带来了更多的安全风险(因为,现在必须保护两个地点了)。关于此问题和管理中的其他实际问题,请参考(Nemeth等人,2000)。接下来我们只讨论文件系统备份所涉及的技术问题。
转储磁盘到磁带上有两种方案:物理转储和逻辑转储。物理转储是从磁盘的第0块开始,将全部的磁盘块按序输出到磁带上,直到最后一块复制完毕。此程序很简单,可以确保万无一失,这是其他任何实用程序所不能比的。
不过有几点关于物理转储的评价还是值得一提的。首先,未使用的磁盘块无须备份。如果转储程序能够得到访问空闲块的数据结构,就可以避免该程序备份未使用的磁盘块。但是,既然磁带上的第k块并不代表磁盘上的第k块,那么要想略过未使用的磁盘块就需要在每个磁盘块前边写下该磁盘块的号码(或其他等效数据)。
第二个需要关注的是坏块的转储。制造大型磁盘而没有任何瑕疵几乎是不可能的,总是有一些坏块存在。有时进行低级格式化后,坏块会被检测出来,标记为坏的,并被应对这种紧急状况的在每个轨道末端的一些空闲块所替换。在很多情况下,磁盘控制器处理坏块的替换过程是透明的,甚至操作系统也不知道。
然而,有时格式化后块也会变坏,在这种情况下操作系统可以检测到它们。通常,可以通过建立一个包含所有坏块的“文件”来解决这个问题——只要确保它们不会出现在空闲块池中并且决不会被分配。不用说,这个文件是完全不能够读取的。
如果磁盘控制器将所有坏块重新映射,并对操作系统隐藏的话,物理转储工作还是能够顺利进行的。另一方面,如果这些坏块对操作系统可见并映射到在一个或几个坏块文件或者位图中,那么在转储过程中,物理转储程序绝对有必要能访问这些信息,并避免转储之,从而防止在对坏块文件备份时的无止境磁盘读错误发生。
物理转储的主要优点是简单、极为快速(基本上是以磁盘的速度运行)。主要缺点是,既不能跳过选定的目录,也无法增量转储,还不能满足恢复个人文件的请求。正因如此,绝大多数配置都使用逻辑转储。
逻辑转储从一个或几个指定的目录开始,递归地转储其自给定基准日期(例如,最近一次增量转储或全面系统转储的日期)后有所更改的全部文件和目录。所以,在逻辑转储中,转储磁带上会有一连串精心标识的目录和文件,这样就很容易满足恢复特定文件或目录的请求。
既然逻辑转储是最为普遍的形式,就让我们以图4-25为例来仔细研究一个通用算法。该算法在UNIX系统上广为使用。在图中可以看到一棵由目录(方框)和文件(圆圈)组成的文件树。被阴影覆盖的项目代表自基准日期以来修改过,因此需要转储,无阴影的则不需要转储。
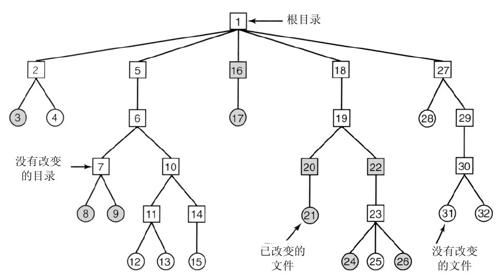
该算法还转储通向修改过的文件或目录的路径上的所有目录(甚至包括未修改的目录),原因有二。其一是为了将这些转储的文件和目录恢复到另一台计算机的新文件系统中。这样,转储程序和恢复程序就可以在计算机之间进行文件系统的整体转移。
转储被修改文件之上的未修改目录的第二个原因是为了可以对单个文件进行增量恢复(很可能是对愚蠢操作所损坏文件的恢复)。设想如果星期天晚上转储了整个文件系统,星期一晚上又做了一次增量转储。在星期二,/usr/jhs/proj/nr3目录及其下的全部目录和文件被删除了。星期三一大早用户又想恢复/usr/jhs/proj/nr3/plans/summary文件。但因为没有设置,所以不可能单独恢复summary文件。必须首先恢复nr3和plans这两个目录。为了正确获取文件的所有者、模式、时间等各种信息,这些目录当然必须再次备份到转储磁带上,尽管自上次完整转储以来它们并没有修改过。
逻辑转储算法要维持一个以i节点号为索引的位图,每个i节点包含了几位。随着算法的执行,位图中的这些位会被设置或清除。算法的执行分为四个阶段。第一阶段从起始目录(本例中为根目录)开始检查其中的所有目录项。对每一个修改过的文件,该算法将在位图中标记其i节点。算法还标记并递归检查每一个目录(不管是否修改过)。
第一阶段结束时,所有修改过的文件和全部目录都在位图中标记了,如图4-26a所示(以阴影标记)。理论上说来,第二阶段再次递归地遍历目录树,并去掉目录树中任何不包含被修改过的文件或目录的目录上的标记。本阶段的执行结果如图4-26b所示。注意,i节点号为10、11、14、27、29和30的目录此时已经被去掉标记,因为它们所包含的内容没有做任何修改。它们因而也不会被转储。相反,i节点号为5和6的目录尽管没有被修改过也要被转储,因为到新的机器上恢复当日的修改时需要这些信息。为了提高算法效率,可以将这两阶段的目录树遍历合二为一。
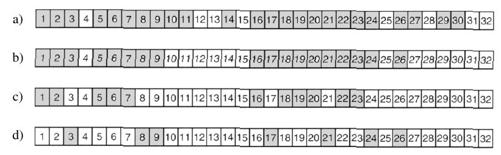
现在哪些目录和文件必须被转储已经很明确了,就是图4-26b中所标记的部分。第三阶段算法将以节点号为序,扫描这些i节点并转储所有标记的目录,如图4-26c所示。为了进行恢复,每个被转储的目录都用目录的属性(所有者、时间等)作为前缀。最后,在第四阶段,在图4-26d中被标记的文件也被转储,同样,由其文件属性作为前缀。至此,转储结束。
从转储磁带上恢复文件系统很容易办到。首先要在磁盘上创建一个空的文件系统,然后恢复最近一次的完整转储。由于磁带上最先出现目录,所以首先恢复目录,给出文件系统的框架;然后恢复文件本身。在完整转储之后的是增量转储,重复这一过程,以此类推。
尽管逻辑转储十分简单,还是有几点棘手之处。首先,既然空闲块列表并不是一个文件,那么在所有被转储的文件恢复完毕之后,就需要从零开始重新构造。这一点可以办到,因为全部空闲块的集合恰好是包含在全部文件中的块集合的补集。
另一个问题是关于连接。如果一个文件被连接到两个或多个目录中,要注意在恢复时只对该文件恢复一次,然后要恢复所有指向该文件的目录。
还有一个问题就是:UNIX文件实际上包含了许多“空洞”。打开文件,写几个字节,然后找到文件中一个偏移了一定距离的地址,又写入更多的字节,这么做是合法的。但两者之间的这些块并不属于文件本身,从而也不应该在其上实施转储和恢复操作。核心文件通常在数据段和堆栈段之间有一个数百兆字节的空洞。如果处理不得当,每个被恢复的核心文件会以“0”填充这些区域,这可能导致该文件与虚拟地址空间一样大(例如,232 字节,更糟糕可能会达到264 字节)。
最后,无论属于哪一个目录(它们并不一定局限于/dev目录下),特殊文件、命名管道以及类似的文件都不应该转储。关于文件系统备份的更多信息,请参考(Chervenak等人,1998;Zwicky,1991)。
磁带密度不会像磁盘密度那样改进得那么快。这会逐渐导致备份一个很大的磁盘需要多个磁带的状况。当磁带机器人可以自动换磁带时,如果这种趋势继续下去,作为一种备份介质,磁带会最终变得太小。在那种情况下,备份一个磁盘的惟一的方式是在另一个磁盘上。对每一个磁盘直接做镜像是一种方式。一个更加复杂的方案,称为RAID,将会在第5章讨论。










