预计阅读本页时间:-

4.4.4 文件系统性能
访问磁盘比访问内存慢得多。读内存中一个32位字大概要10ns。从硬盘上读的速度大约超过100MB/s,对32位字来说,大约要慢4倍,还要加上5~10ms寻道时间,并等待所需的扇面抵达磁头下。如果只需要一个字,内存访问则比磁盘访问快百万数量级。考虑到访问时间的这个差异,许多文件系统采用了各种优化措施以改善性能。本节我们将介绍其中三种方法。
1.高速缓存
最常用的减少磁盘访问次数技术是块高速缓存(block cache)或者缓冲区高速缓存(buffer cache)。在本书中,高速缓存指的是一系列的块,它们在逻辑上属于磁盘,但实际上基于性能的考虑被保存在内存中。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
管理高速缓存有不同的算法,常用的算法是:检查全部的读请求,查看在高速缓存中是否有所需要的块。如果存在,可执行读操作而无须访问磁盘。如果该块不在高速缓存中,首先要把它读到高速缓存,再复制到所需地方。之后,对同一个块的请求都通过高速缓存完成。
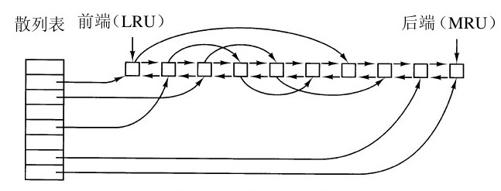
高速缓存的操作如图4-28所示。由于在高速缓存中有许多块(通常有上千块),所以需要有某种方法快速确定所需要的块是否存在。常用方法是将设备和磁盘地址进行散列操作,然后,在散列表中查找结果。具有相同散列值的块在一个链表中连接在一起,这样就可以沿着冲突链查找其他块。
如果高速缓存已满,则需要调入新的块,因此,要把原来的某一块调出高速缓存(如果要调出的块在上次调入以后修改过,则要把它写回磁盘)。这种情况与分页非常相似,所有常用的页面置换算法在第3章中已经介绍,例如FIFO算法、第二次机会算法、LRU算法等,它们都适用于高速缓存。与分页相比,高速缓存的好处在于对高速缓存的引用不很频繁,所以按精确的LRU顺序在链表中记录全部的块是可行的。
在图4-28中可以看到,除了散列表中的冲突链之外,还有一个双向链表把所有的块按照使用时间的先后次序链接起来,近来使用最少的块在该链表的前端,而近来使用最多的块在该链表的后端。当引用某个块时,该块可以从双向链表中移走,并放置到该表的尾部去。用这种方法,可以维护一种准确的LRU顺序。
但是,这又带来了意想不到的难题。现在存在一种情形,使我们有可能获得精确的LRU,但是碰巧该LRU却又不符合要求。这个问题与前一节讨论的系统崩溃和文件一致性有关。如果一个关键块(比如i节点块)读进了高速缓存并做过修改,但是没有写回磁盘,这时,系统崩溃会导致文件系统的不一致。如果把i节点块放在LRU链的尾部,在它到达链首并写回磁盘前,有可能需要相当长的一段时间。
此外,某一些块,如i节点块,极少可能在短时间内被引用两次。基于这些考虑需要修改LRU方案,并应注意如下两点:
1)这一块是否不久后会再次使用?
2)这一块是否关系到文件系统的一致性?
考虑以上两个问题时,可将块分为i节点块、间接块、目录块、满数据块、部分数据块等几类。把有可能最近不再需要的块放在LRU链表的前部,而不是LRU链表的后端,于是它们所占用的缓冲区可以很快被重用。对很快就可能再次使用的块,比如正在写入的部分满数据块,可放在链表的尾部,这样它们能在高速缓存中保存较长的一段时间。
第二个问题独立于前一个问题。如果关系到文件系统一致性(除数据块之外,其他块基本上都是这样)的某块被修改,都应立即将该块写回磁盘,不管它是否被放在LRU链表尾部。将关键块快速写回磁盘,将大大减少在计算机崩溃后文件系统被破坏的可能性。用户的文件崩溃了,该用户会不高兴,但是如果整个文件系统都丢失了,那么这个用户会更生气。
尽管用这类方法可以保证文件系统一致性不受到破坏,但我们仍然不希望数据块在高速缓存中放很久之后才写入磁盘。设想某人正在用个人计算机编写一本书。尽管作者让编辑程序将正在编辑的文件定期写回磁盘,所有的内容只存在高速缓存中而不在磁盘上的可能性仍然非常大。如果这时系统崩溃,文件系统的结构并不会被破坏,但他一整天的工作就会丢失。
即使只发生几次这类情况,也会让人感到不愉快。系统采用两种方法解决这一问题。在UNIX系统中有一个系统调用sync,它强制性地把全部修改过的块立即写回磁盘。系统启动时,在后台运行一个通常名为update的程序,它在无限循环中不断执行sync调用,每两次调用之间休眠30s。于是,系统即使崩溃,也不会丢失超过30秒的工作。
虽然目前Windows有一个等价于sync的系统调用——FlushFileBuffers,不过过去没有。相反,Windows采用一个在某种程度上比UNIX方式更好(有时更坏)的策略。其做法是,只要被写进高速缓存,就把每个被修改的块写进磁盘。将缓存中所有被修改的块立即写回磁盘称为通写高速缓存(write-through cache)。同非通写高速缓存相比,通写高速缓存需要更多的磁盘I/O。
若某程序要写满1KB的块,每次写一个字符,这时可以看到这两种方法的区别。UNIX在高速缓存中保存全部字符,并把这个块每30秒写回磁盘一次,或者当从高速缓存删除这一块时,写回磁盘。在通写高速缓存里,每写入一字符就要访问一次磁盘。当然,多数程序有内部缓冲,通常情况下,在每次执行write系统调用时并不是只写入一个字符,而是写入一行或更大的单位。
采用这两种不同的高速缓存策略的结果是:在UNIX系统中,若不调用sync就移动(软)磁盘,往往会导致数据丢失,在被毁坏的文件系统中也经常如此。而在通写高速缓存中,就不会出现这类情况。选择不同策略的原因是,在UNIX开发环境中,全部磁盘都是硬盘,不可移动。而第一代Windows文件源自MS-DOS,是从软盘世界中发展起来的。由于UNIX方案有更高的效率它成为当然的选择(但可靠性更差),随着硬盘成为标准,它目前也用在Windows的磁盘上。但是,NTFS使用其他方法(日志)改善其可靠性,这在前面已经讨论过。
一些操作系统将高速缓存与页缓存集成。这种方式特别是在支持内存映射文件的时候很吸引人。如果一个文件被映射到内存上,则它其中的一些页就会在内存中,因为它们被要求按页进入。这些页面与在高速缓存中的文件块几乎没有不同。在这种情况下,它们能被以同样的方式来对待,也就是说,用一个缓存来同时存储文件块与页。
2.块提前读
第二个明显提高文件系统性能的技术是:在需要用到块之前,试图提前将其写入高速缓存,从而提高命中率。特别地,许多文件都是顺序读的。如果请求文件系统在某个文件中生成块k,文件系统执行相关操作且在完成之后,会在用户不察觉的情形下检查高速缓存,以便确定块k+1是否已经在高速缓存。如果还不在,文件系统会为块k+1安排一个预读,因为文件系统希望在需要用到该块时,它已经在高速缓存或者至少马上就要在高速缓存中了。
当然,块提前读策略只适用于顺序读取的文件。对随机存取文件,提前读丝毫不起作用。相反,它还会帮倒忙,因为读取无用的块以及从高速缓存中删除潜在有用的块将会占用固定的磁盘带宽(如果有“脏”块的话,还需要将它们写回磁盘,这就占用了更多的磁盘带宽)。那么提前读策略是否值得采用呢?文件系统通过跟踪每一个打开文件的访问方式来确定这一点。例如,可以使用与文件相关联的某个位协助跟踪该文件到底是“顺序存取方式”还是“随机存取方式”。在最初不能确定文件属于哪种存取方式时,先将该位设置成顺序存取方式。但是,查找一完成,就将该位清除。如果再次发生顺序读取,就再次设置该位。这样,文件系统可以通过合理的猜测,确定是否应该采取提前读的策略。即便弄错了一次也不会产生严重后果,不过是浪费一小段磁盘的带宽罢了。
3.减少磁盘臂运动
高速缓存和块提前读并不是提高文件系统性能的惟一方法。另一种重要技术是把有可能顺序存取的块放在一起,当然最好是在同一个柱面上,从而减少磁盘臂的移动次数。当写一个输出文件时,文件系统就必须按照要求一次一次地分配磁盘块。如果用位图来记录空闲块,并且整个位图在内存中,那么选择与前一块最近的空闲块是很容易的。如果用空闲表,并且链表的一部分存在磁盘上,要分配紧邻着的空闲块就困难得多。
不过,即使采用空闲表,也可以采用块簇技术。这里用到一个小技巧,即不用块而用连续块簇来跟踪磁盘存储区。如果一个扇区有512个字节,有可能系统采用1KB的块(2个扇区),但却按每2块(4个扇区)一个单位来分配磁盘存储区。这和2KB的磁盘块并不相同,因为在高速缓存中它依然使用1KB的块,磁盘与内存数据之间传送也是以1KB为单位进行,但在一个空闲的系统上顺序读取文件,寻道的次数可以减少一半,从而使文件系统的性能大大改善。若考虑旋转定位则可以得到这类方案的变体。在分配块时,系统尽量把一个文件中的连续块存放在同一柱面上。
在使用i节点或任何类似i节点的系统中,另一个性能瓶颈是,读取一个很短的文件也需要两次磁盘访问:一次是访问i节点,另一次是访问块。通常情况下,i节点的放置如图4-29a所示。其中,全部i节点都放在靠近磁盘开始位置,所以i节点和它指向的块之间的平均距离是柱面数的一半,这将需要较长的寻道时间。
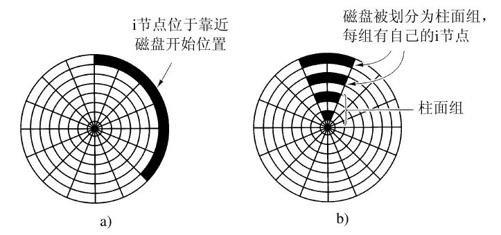
一个简单的改进方法是,在磁盘中部而不是开始处存放i节点,此时,在i节点和第一块之间的平均寻道时间减为原来的一半。另一种做法是:将磁盘分成多个柱面组,每个柱面组有自己的i节点、数据块和空闲表(McKusick等人,1984),见图4-29b。在文件创建时,可选取任一i节点,但首先在该i节点所在的柱面组上查找块。如果在该柱面组中没有空闲的块,就选用与之相邻的柱面组的一个块。










