预计阅读本页时间:-

5.1.3 内存映射I/O
每个控制器有几个寄存器用来与CPU进行通信。通过写入这些寄存器,操作系统可以命令设备发送数据、接收数据、开启或关闭,或者执行某些其他操作。通过读取这些寄存器,操作系统可以了解设备的状态,是否准备好接收一个新的命令等。
除了这些控制寄存器以外,许多设备还有一个操作系统可以读写的数据缓冲区。例如,在屏幕上显示像素的常规方法是使用一个视频RAM,这一RAM基本上只是一个数据缓冲区,可供程序或操作系统写入数据。
于是,问题就出现了:CPU如何与设备的控制寄存器和数据缓冲区进行通信?存在两个可选的方法。在第一个方法中,每个控制寄存器被分配一个I/O端口(I/O port)号,这是一个8位或16位的整数。所有I/O端口形成I/O端口空间(I/O port space),并且受到保护使得普通的用户程序不能对其进行访问(只有操作系统可以访问)。使用一条特殊的I/O指令,例如
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
IN REG,PORT
CPU可以读取控制寄存器PORT的内容并将结果存入到CPU寄存器REG中。类似地,使用
OUT PORT,REG
CPU可以将REG的内容写入到控制寄存器中。大多数早期计算机,包括几乎所有大型主机,如IBM 360及其所有后续机型,都是以这种方式工作的。
在这一方案中,内存地址空间和I/O地址空间是不同的,如图5-2a所示。指令
IN R0,4
和
MOV R0,4
在这一设计中完全不同。前者读取I/O端口4的内容并将其存入R0,而后者则读取内存字4的内容并将其存入R0。因此,这些例子中的4引用的是不同且不相关的地址空间。
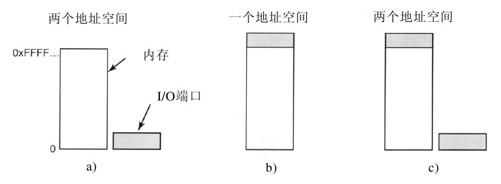
第二个方法是PDP-11引入的,它将所有控制寄存器映射到内存空间中,如图5-2b所示。每个控制寄存器被分配惟一的一个内存地址,并且不会有内存被分配这一地址。这样的系统称为内存映射I/O(memory-mapped I/O)。通常分配给控制寄存器的地址位于地址空间的顶端。图5-2c所示是一种混合的方案,这一方案具有内存映射I/O的数据缓冲区,而控制寄存器则具有单独的I/O端口。Pentium处理器使用的就是这一体系结构。在IBM PC兼容机中,除了0到64K-1的I/O端口之外,640K到1M-1的地址保留给设备的数据缓冲区。
这些方案是怎样工作的?在各种情形下,当CPU想要读入一个字的时候,不论是从内存中读入还是从I/O端口中读入,它都要将需要的地址放到总线的地址线上,然后在总线的一条控制线上置起一个READ信号。还要用到第二条信号线来表明需要的是I/O空间还是内存空间。如果是内存空间,内存将响应请求。如果是I/O空间,I/O设备将响应请求。如果只有内存空间(如图5-2b所示的情形),那么每个内存模块和每个I/O设备都会将地址线和它所服务的地址范围进行比较,如果地址落在这一范围之内,它就会响应请求。因为绝对不会有地址既分配给内存又分配给I/O设备,所以不会存在歧义和冲突。
这两种寻址控制器的方案具有不同的优缺点。我们首先来看一看内存映射I/O的优点。第一,如果需要特殊的I/O指令读写设备控制寄存器,那么访问这些寄存器需要使用汇编代码,因为在C或C++中不存在执行IN或OUT指令的方法。调用这样的过程增加了控制I/O的开销。相反,对于内存映射I/O,设备控制寄存器只是内存中的变量,在C语言中可以和任何其他变量一样寻址。因此,对于内存映射I/O,I/O设备驱动程序可以完全用C语言编写。如果不使用内存映射I/O,就要用到某些汇编代码。
第二,对于内存映射I/O,不需要特殊的保护机制来阻止用户进程执行I/O操作。操作系统必须要做的全部事情只是避免把包含控制寄存器的那部分地址空间放入任何用户的虚拟地址空间之中。更为有利的是,如果每个设备在地址空间的不同页面上拥有自己的控制寄存器,操作系统只要简单地通过在其页表中包含期望的页面就可以让用户控制特定的设备而不是其他设备。这样的方案可以使不同的设备驱动程序放置在不同的地址空间中,不但可以减小内核的大小,而且可以防止驱动程序之间相互干扰。
第三,对于内存映射I/O,可以引用内存的每一条指令也可以引用控制寄存器。例如,如果存在一条指令TEST可以测试一个内存字是否为0,那么它也可以用来测试一个控制寄存器是否为0,控制寄存器为0可以作为信号,表明设备空闲并且可以接收一条新的命令。汇编语言代码可能是这样的:
LOOP:TEST PORT_4//检测端口4是否为0
BEQ READY//如果为0,转向READY
BRANCH LOOP//否则,继续测试
READY:
如果不是内存映射I/O,那么必须首先将控制寄存器读入CPU,然后再测试,这样就需要两条指令而不是一条。在上面给出的循环的情形中,就必须加上第四条指令,这样会稍稍降低检测空闲设备的响应度。
在计算机设计中,实际上任何事情都要涉及权衡,此处也不例外。内存映射I/O也有缺点。首先,现今大多数计算机都拥有某种形式的内存字高速缓存。对一个设备控制寄存器进行高速缓存可能是灾难性的。在存在高速缓存的情况下考虑上面给出的汇编代码循环。第一次引用PORT_4将导致它被高速缓存,随后的引用将只从高速缓存中取值并且不会再查询设备。之后当设备最终变为就绪时,软件将没有办法发现这一点。结果,循环将永远进行下去。
对内存映射I/O,为了避免这一情形,硬件必须针对每个页面具备选择性禁用高速缓存的能力。操作系统必须管理选择性高速缓存,所以这一特性为硬件和操作系统两者增添了额外的复杂性。
其次,如果只存在一个地址空间,那么所有的内存模块和所有的I/O设备都必须检查所有的内存引用,以便了解由谁做出响应。如果计算机具有单一总线,如图5-3a所示,那么让每个内存模块和I/O设备查看每个地址是简单易行的。
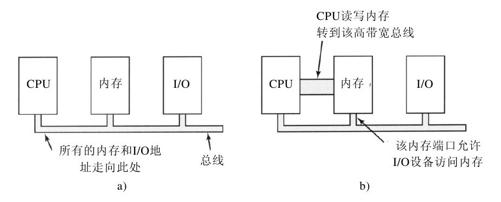
然而,现代个人计算机的趋势是包含专用的高速内存总线,如图5-3b所示。顺便提一句,在大型机中也可以发现这一特性。装备这一总线是为了优化内存性能,而不是为了慢速的I/O设备而做的折中。Pentium系统甚至可以有多种总线(内存、PCI、SCSI、USB、ISA),如图1-12所示。
在内存映射的机器上具有单独的内存总线的麻烦是I/O设备没有办法查看内存地址,因为内存地址旁路到内存总线上,所以没有办法响应。此外,必须采取特殊的措施使内存映射I/O工作在具有多总线的系统上。一种可能的方法是首先将全部内存引用发送到内存,如果内存响应失败,CPU将尝试其他总线。这一设计是可以工作的,但是需要额外的硬件复杂性。
第二种可能的设计是在内存总线上放置一个探查设备,放过所有潜在地指向所关注的I/O设备的地址。此处的问题是,I/O设备可能无法以内存所能达到的速度处理请求。
第三种可能的设计是在PCI桥芯片中对地址进行过滤,这正是图1-12中Pentium结构上所使用的。该芯片中包含若干个在引导时预装载的范围寄存器。例如,640K到1M-1可能被标记为非内存范围。落在标记为非内存的那些范围之内的地址将被转发给PCI总线而不是内存。这一设计的缺点是需要在引导时判定哪些内存地址不是真正的内存地址。因而,每一设计都有支持它和反对它的论据,所以折中和权衡是不可避免的。










