预计阅读本页时间:-

5.4.5 稳定存储器
正如我们已经看到的,磁盘有时会出现错误。好扇区可能突然变成坏扇区,整个驱动器也可能出乎意料地死掉。RAID可以对几个扇区出错或者整个驱动器崩溃提供保护。然而,RAID首先不能对将坏数据写下的写错误提供保护,并且也不能对写操作期间的崩溃提供保护,这样就会破坏原始数据而不能以更新的数据替换它们。
对于某些应用而言,决不丢失或破坏数据是绝对必要的,即使面临磁盘和CPU错误也是如此。理想的情况是,磁盘应该始终没有错误地工作。但是,这是做不到的。所能够做到的是,一个磁盘子系统具有如下特性:当一个写命令发给它时,磁盘要么正确地写数据,要么什么也不做,让现有的数据完整无缺地留下。这样的系统称为稳定存储器(stable storage),并且是在软件中实现的(Lampson和Sturgis,1979)。目标是不惜一切代价保持磁盘的一致性。下面我们将描述这种最初思想的一个微小的变体。
在描述算法之前,重要的是对于可能发生的错误有一个清晰的模型。该模型假设在磁盘写一个块(一个或多个扇区)时,写操作要么是正确的,要么是错误的,并且该错误可以在随后的读操作中通过检查ECC域的值检测出来。原则上,保证错误检测是根本不可能的,这是因为,假如使用一个16字节的ECC域保护一个512字节的扇区,那么存在着24096 个数据值而仅有2144 个ECC值。因此,如果一个块在写操作期间出现错误但是ECC没有出错,那么存在着几亿亿个错误的组合可以产生相同的ECC。如果某些这样的错误出现,则错误不会被检测到。大体上,随机数据具有正确的16字节ECC的概率大约是2-144 。该概率值足够小以至于我们可以视其为零,尽管它实际上并不为零。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
该模型还假设一个被正确写入的扇区可能会自发地变坏并且变得不可读。然而,该假设是:这样的事件非常少见,以至于在合理的时间间隔内(例如1天)让相同的扇区在第二个(独立的)驱动器上变坏的概率小到可以忽略的程度。
该模型还假设CPU可能出故障,在这样的情况下只能停机。在出现故障的时刻任何处于进行中的磁盘写操作也会停止,导致不正确的数据写在一个扇区中并且后来可能会检测到不正确的ECC。在所有这些情况下,稳定存储器就写操作而言可以提供100%的可靠性,要么就正确地工作,要么就让旧的数据原封不动。当然,它不能对物理灾难提供保护,例如,发生地震,计算机跌落100m掉入一个裂缝并且陷入沸腾的岩浆池中,在这样的情况下用软件将其恢复是勉为其难的。
稳定存储器使用一对完全相同的磁盘,对应的块一同工作以形成一个无差错的块。当不存在错误时,在两个驱动器上对应的块是相同的,读取任意一个都可以得到相同的结果。为了达到这一目的,定义了下述三种操作:
1)稳定写(stable write)。稳定写首先将块写到驱动器1上,然后将其读回以校验写的是正确的。如果写的不正确,那么就再次做写和重读操作,一直到n次,直到正常为止。经过n次连续的失败之后,就将该块重映射到一个备用块上,并且重复写和重读操作直到成功为止,无论要尝试多少个备用块。在对驱动器1的写成功之后,对驱动器2上对应的块进行写和重读,如果需要的话就重复这样的操作,直到最后成功为止。如果不存在CPU崩溃,那么当稳定写完成后,块就正确地被写到两个驱动器上,并且在两个驱动器上得到校验。
2)稳定读(stable read)。稳定读首先从驱动器l上读取块。如果这一操作产生错误的ECC,则再次尝试读操作,一直到n次。如果所有这些操作都给出错误的ECC,则从驱动器2上读取对应的数据块。给定一个成功的稳定写为数据块留下两个可靠的副本这样的事实,并且我们假设在合理的时间间隔内相同的块在两个驱动器上自发地变坏的概率可以忽略不计,那么稳定读就总是成功的。
3)崩溃恢复(crash recovery)。崩溃之后,恢复程序扫描两个磁盘,比较对应的块。如果一对块都是好的并且是相同的,就什么都不做。如果其中一个具有ECC错误,那么坏块就用对应的好块来覆盖。如果一对块都是好的但是不相同,那么就将驱动器1上的块写到驱动器2上。
如果不存在CPU崩溃,那么这一方法总是可行的,因为稳定写总是对每个块写下两个有效的副本,并且假设自发的错误决不会在相同的时刻发生在两个对应的块上。如果在稳定写期间出现CPU崩溃会怎么样?这就取决于崩溃发生的精确时间。有5种可能性,如图5-31所示。
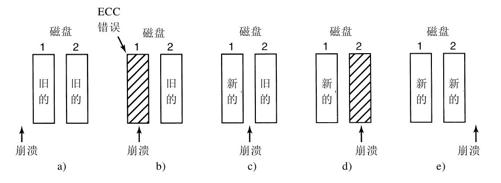
在图5-31a中,CPU崩溃发生在写块的两个副本之前。在恢复的时候,什么都不用修改而旧的值将继续存在,这是允许的。
在图5-31b中,CPU崩溃发生在写驱动器1期间,破坏了该块的内容。然而恢复程序能够检测出这一错误,并且从驱动器2恢复驱动器1上的块。因此,这一崩溃的影响被消除并且旧的状态完全被恢复。
在图5-31c中,CPU崩溃发生在写完驱动器1之后但是还没有写驱动器2之前。此时已经过了无法复原的时刻:恢复程序将块从驱动器1复制到驱动器2上。写是成功的。
图5-31d与图5-31b相类似:在恢复期间用好的块覆盖坏的块。不同的是,两个块的最终取值都是新的。
最后,在图5-31e中,恢复程序看到两个块是相同的,所以什么都不用修改并且在此处写也是成功的。
对于这一模式进行各种各样的优化和改进都是可能的。首先,在崩溃之后对所有的块两个两个地进行比较是可行的,但是代价高昂。一个巨大的改进是在稳定写期间跟踪被写的是哪个块,这样在恢复的时候必须被检验的块就只有一个。某些计算机拥有少量的非易失性RAM(nonvolatile RAM),它是一个特殊的CMOS存储器,由锂电池供电。这样的电池能够维持很多年,甚至有可能是计算机的整个生命周期。与主存不同(它在崩溃之后就丢失了),非易失性RAM在崩溃之后并不丢失。每天的时间通常就保存在这里(并且通过一个特殊的电路进行增值),这就是为什么计算机即使在拔掉电源之后仍然知道是什么时间。
假设非易失性RAM的几个字节可供操作系统使用,稳定写就可以在开始写之前将准备要更新的块的编号放到非易失性RAM里。在成功地完成稳定写之后,在非易失性RAM中的块编号用一个无效的块编号(例如-1)覆盖掉。在这些情形下,崩溃之后恢复程序可以检验非易失性RAM以了解在崩溃期间是否有一个稳定写正在进行中,如果是的话,还可以了解在崩溃发生的时候被写的是哪一个块。然后,可以对块的两个副本进行正确性和一致性检验。
如果没有非易失性RAM可用,可以对它模拟如下。在稳定写开始时,用将要被稳定写的块的编号覆盖驱动器1上的一个固定的块,然后读回该块以对其进行校验。在使得该块正确之后,对驱动器2上对应的块进行写和校验。当稳定写正确地完成时,用一个无效的块编号覆盖两个块并进行校验。这样一来,崩溃之后就很容易确定在崩溃期间是否有一个稳定写正在进行中。当然,这一技术为了写一个稳定的块需要8次额外的磁盘操作,所以应该极少量地应用该技术。
还有最后一点值得讨论。我们假设每天每一对块只发生一个好块自发损坏成为坏块。如果经过足够长的时间,另一个块也可能变坏。因此,为了修复任何损害每天必须对两块磁盘进行一次完整的扫描。这样,每天早晨两块磁盘总是一模一样的。即便在一个时期内一对中的两个块都坏了,所有的错误也都能正确地修复。










