预计阅读本页时间:-

8.1.2 多处理机操作系统类型
让我们从对多处理机硬件的讨论转到多处理机软件,特别是多处理机操作系统上来。这里有各种可能的方法。接下来将讨论其中的三种。需要强调的是所有这些方法除了适用于多核系统之外,同样适用于包含多个分离CPU的系统。
1.每个CPU有自己的操作系统
组织一个多处理机操作系统的可能的最简单的方法是,静态地把存储器划分成和CPU一样多的各个部分,为每个CPU提供其私有存储器以及操作系统的各自私有副本。实际上n个CPU以n个独立计算机的形式运行。这样做一个明显的优点是,允许所有的CPU共享操作系统的代码,而且只需要提供数据的私有副本,如图8-7所示。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
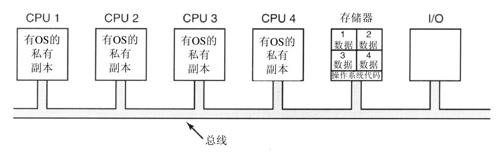
这一机制比有n个分离的计算机要好,因为它允许所有的机器共享一套磁盘及其他的I/O设备,它还允许灵活地共享存储器。例如,即便使用静态内存分配,一个CPU也可以获得极大的一块内存,从而高效地执行代码。另外,由于生产者能够直接把数据写入存储器,从而使得消费者从生产者写入的位置取出数据,因此进程之间可以高效地通信。况且,从操作系统的角度看,每个CPU都有自己的操作系统非常自然。
值得提及该设计看来不明显的四个方面。首先,在一个进程进行系统调用时,该系统调用是在本机的CPU上被捕获并处理的,并使用操作系统表中的数据结构。
其次,因为每个操作系统都有自己的表,那么它也有自己的进程集合,通过自身调度这些进程。这里没有进程共享。如果一个用户登录到CPU 1,那么他的所有进程都在CPU 1上运行。因此,在CPU 2有负载运行而CPU 1空载的情形是会发生的。
第三,没有页面共享。会出现如下的情形:在CPU2不断地进行页面调度时CPU 1却有多余的页面。由于内存分配是固定的,所以CPU 2无法向CPU 1借用页面。
第四,也是最坏的情形,如果操作系统维护近期使用过的磁盘块的缓冲区高速缓存,每个操作系统都独自进行这种维护工作,因此,可能出现某一修改过的磁盘块同时存在于多个缓冲区高速缓存的情况,这将会导致不一致性的结果。避免这一问题的惟一途径是,取消缓冲区高速缓存。这样做并不难,但是会显著降低性能。
由于这些原因,上述模型已很少使用,尽管在早期的多处理机中它一度被采用,那时的目标是把已有的操作系统尽可能快地移植到新的多处理机上。
2.主从多处理机
图8-8中给出的是第二种模型。在这种模型中,操作系统的一个副本及其数据表都在CPU 1上,而不是在其他所有CPU上。为了在该CPU 1上进行处理,所有的系统调用都重定向到CPU 1上。如果有剩余的CPU时间,还可以在CPU 1上运行用户进程。这种模型称为主从模型(master-slave),因为CPU 1是主CPU,而其他的都是从属CPU。
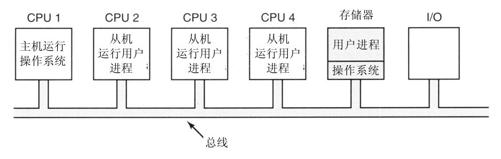
主从模型解决了在第一种模型中的多数问题。有单一的数据结构(如一个链表或者一组优先级链表)用来记录就绪进程。当某个CPU空闲下来时,它向CPU 1上的操作系统请求一个进程运行,并被分配一个进程。这样,就不会出现一个CPU空闲而另一个过载的情形。类似地,可在所有的进程中动态地分配页面,而且只有一个缓冲区高速缓存,所以决不会出现不一致的情形。
这个模型的问题是,如果有很多的CPU,主CPU会变成一个瓶颈。毕竟,它要处理来自所有CPU的系统调用。如果全部时间的10%用来处理系统调用,那么10个CPU就会使主CPU饱和,而20个CPU就会使主CPU彻底过载。可见,这个模型虽然简单,而且对小型多处理机是可行的,但不能用于大型多处理机。
3.对称多处理机
我们的第三种模型,即对称多处理机(Symmetric MultiProcessor,SMP),消除了上述的不对称性。在存储器中有操作系统的一个副本,但任何CPU都可以运行它。在有系统调用时,进行系统调用的CPU陷入内核并处理系统调用。图8-9是对SMP模式的说明。
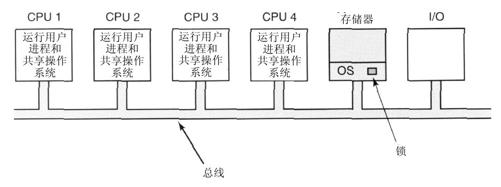
这个模型动态地平衡进程和存储器,因为它只有一套操作系统数据表。它还消除了主CPU的瓶颈,因为不存在主CPU;但是这个模型也带来了自身的问题。特别是,当两个或更多的CPU同时运行操作系统代码时,就会出现灾难。想象有两个CPU同时选择相同的进程运行或请求同一个空闲存储器页面。处理这些问题的最简单方法是在操作系统中使用互斥信号量(锁),使整个系统成为一个大临界区。当一个CPU要运行操作系统时,它必须首先获得互斥信号量。如果互斥信号量被锁住,就得等待。按照这种方式,任何CPU都可以运行操作系统,但在任一时刻只有一个CPU可运行操作系统。
这个模型是可以工作的,但是它几乎同主从模式一样糟糕。同样假设,如果所有时间的10%花费在操作系统内部。那么在有20个CPU时,会出现等待进入的CPU长队。幸运的是,比较容易进行改进。操作系统中的很多部分是彼此独立的。例如,在一个CPU运行调度程序时,另一个CPU则处理文件系统的调用,而第三个在处理一个缺页异常,这种运行方式是没有问题的。
这一事实使得把操作系统分割成互不影响的临界区。每个临界区由其互斥信号量保护,所以一次只有一个CPU可执行它。采用这种方式,可以实现更多的并行操作。而某些表格,如进程表,可能恰巧被多个临界区使用。例如,在调度时需要进程表,在系统fork调用和信号处理时也都需要进程表。多临界区使用的每个表格,都需要有各自的互斥信号量。通过这种方式,可以做到每个临界区在任一个时刻只被一个CPU执行,而且在任一个时刻每个临界表(critical table)也只被一个CPU访问。
大多数的现代多处理机都采用这种安排。为这类机器编写操作系统的困难,不在于其实际的代码与普通的操作系统有多大的不同,而在于如何将其划分为可以由不同的CPU并行执行的临界区而互不干扰,即使以细小的、间接的方式。另外,对于被两个或多个临界区使用的表必须通过互斥信号量分别加以保护,而且使用这些表的代码必须正确地运用互斥信号量。
更进一步,必须格外小心地避免死锁。如果两个临界区都需要表A和表B,其中一个首先申请A,另一个首先申请B,那么迟早会发生死锁,而且没有人知道为什么会发生死锁。理论上,所有的表可以被赋予整数值,而且所有的临界区都应该以升序的方式获得表。这一策略避免了死锁,但是需要程序员非常仔细地考虑每个临界区需要哪个表,以便按照正确的次序安排请求。
由于代码是随着时间演化的,所以也许有个临界区需要一张过去不需要的新表。如果程序员是新接手工作的,他不了解系统的整个逻辑,那么可能只是在他需要的时候获得表,并且在不需要时释放掉。尽管这看起来是合理的,但是可能会导致死锁,即用户会觉察到系统被凝固住了。要做正确并不容易,而且要在程序员不断更换的数年时间之内始终保持正确性太困难了。










