预计阅读本页时间:-

8.1.3 多处理机同步
在多处理机中CPU经常需要同步。这里刚刚看到了内核临界区和表被互斥信号量保护的情形。现在让我们仔细看看在多处理机中这种同步是如何工作的。正如我们将看到的,它远不是那么无足轻重。
开始讨论之前,还需要引入同步原语。如果一个进程在单处理机(仅含一个CPU)中需要访问一些内核临界表的系统调用,那么内核代码在接触该表之前可以先禁止中断。然后它继续工作,在相关工作完成之前,不会有任何其他的进程溜进来访问该表。在多处理机中,禁止中断的操作只影响到完成禁止中断操作的这个CPU,其他的CPU继续运行并且可以访问临界表。因此,必须采用一种合适的互斥信号量协议,而且所有的CPU都遵守该协议以保证互斥工作的进行。
任何实用的互斥信号量协议的核心都是一条特殊指令,该指令允许检测一个存储器字并以一种不可见的操作设置。我们来看看在图2-22中使用的指令TSL(Test and Set Lock)是如何实现临界区的。正如我们先前讨论的,这条指令做的是,读出一个存储器字并把它存储在一个寄存器中。同时,它对该存储器字写入一个1(或某些非零值)。当然,这需要两个总线周期来完成存储器的读写。在单处理机中,只要该指令不被中途中断,TSL指令就始终照常工作。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
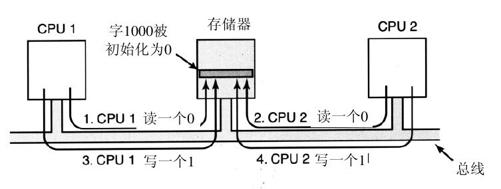
现在考虑在一个多处理机中发生的情况。在图8-10中我们看到了最坏情况的时序,其中存储器字1000,被用作一个初始化为0的锁。第1步,CPU 1读出该字得到一个0。第2步,在CPU 1有机会把该字写为1之前,CPU 2进入,并且也读出该字为0。第3步,CPU 1把1写入该字。第4步,CPU 2也把1写入该字。两个CPU都由TSL指令得到0,所以两者都对临界区进行访问,并且互斥失败。
为了阻止这种情况的发生,TSL指令必须首先锁住总线,阻止其他的CPU访问它,然后进行存储器的读写访问,再解锁总线。对总线加锁的典型做法是,先使用通常的总线协议请求总线,并申明(设置一个逻辑1)已拥有某些特定的总线线路,直到两个周期全部完成。只要始终保持拥有这一特定的总线线路,那么其他CPU就不会得到总线的访问权。这个指令只有在拥有必要的线路和和使用它们的(硬件)协议上才能实现。现代总线有这些功能,但是早期的一些总线不具备,它们不能正确地实现TSL指令。这就是Peterson协议(完全用软件实现同步)会产生的原因(Peterson,1981)。
如果正确地实现和使用TSL,它能够保证互斥机制正常工作。但是这种互斥方法使用了自旋锁(spin lock),因为请求的CPU只是在原地尽可能快地对锁进行循环测试。这样做不仅完全浪费了提出请求的各个CPU的时间,而且还给总线或存储器增加了大量的负载,严重地降低了所有其他CPU从事正常工作的速度。
乍一看,高速缓存的实现也许能够消除总线竞争的问题,但事实并非如此。理论上,只要提出请求的CPU已经读取了锁字(lock word),它就可在其高速缓存中得到一个副本。只要没有其他CPU试图使用该锁,提出请求的CPU就能够用完其高速缓存。当拥有锁的CPU写入一个1到高速缓存并释放它时,高速缓存协议会自动地将它在远程高速缓存中的所有副本失效,要求再次读取正确的值。
问题是,高速缓存操作是在32或64字节的块中进行的。通常,拥有锁的CPU也需要这个锁周围的字。由于TSL指令是一个写指令(因为它修改了锁),所以它需要互斥地访问含有锁的高速缓存块。这样,每一个TSL都使锁持有者的高速缓存中的块失效,并且为请求的CPU取一个私有的、惟一的副本。只要锁拥有者访问到该锁的邻接字,该高速缓存块就被送进其机器。这样一来,整个包含锁的高速缓存块就会不断地在锁的拥有者和锁的请求者之间来回穿梭,导致了比单个读取一个锁字更大的总线流量。
如果能消除在请求一侧的所有由TSL引起的写操作,我们就可以明显地减少这种开销。使提出请求的CPU首先进行一个纯读操作来观察锁是否空闲,就可以实现这个目标。只有在锁看来是空闲时,TSL才真正去获取它。这种小小变化的结果是,大多数的行为变成读而不是写。如果拥有锁的CPU只是在同一个高速缓存块中读取各种变量,那么它们每个都可以以共享只读方式拥有一个高速缓存块的副本,这就消除了所有的高速缓存块传送。当锁最终被释放时,锁的所有者进行写操作,这需要排它访问,也就使远程高速缓存中的所有其他副本失效。在提出请求的CPU的下一个读请求中,高速缓存块会被重新装载。注意,如果两个或更多的CPU竞争同一个锁,那么有可能出现这样的情况,两者同时看到锁是空闲的,于是同时用TSL指令去获得它。只有其中的一个会成功,所以这里没有竞争条件,因为真正的获取是由TSL指令进行的,而且这条指令是原子性的。即使看到了锁空闲,然后立即用TSL指令试图获得它,也不能保证真正得到它。其他CPU可能会取胜,不过对于该算法的正确性来说,谁得到了锁并不重要。纯读出操作的成功只是意味着这可能是一个获得锁的好时机,但并不能确保能成功地得到锁。
另一个减少总线流量的方式是使用著名的以太网二进制指数补偿算法(binary exponential backoff algorithm)(Anderson,1990)。不是采用连续轮询,参考图2-22,而是把一个延迟循环插入轮询之间。初始的延迟是一条指令。如果锁仍然忙,延迟被加倍成为两条指令,然后,四条指令,如此这样进行,直到某个最大值。当锁释放时,较低的最大值会产生快速的响应。但是会浪费较多的总线周期在高速缓存的颠簸上。而较高的最大值可减少高速缓存的颠簸,但是其代价是不会注意到锁如此迅速地成为空闲。二进制指数补偿算法无论在有或无TSL指令前的纯读的情况下都适用。
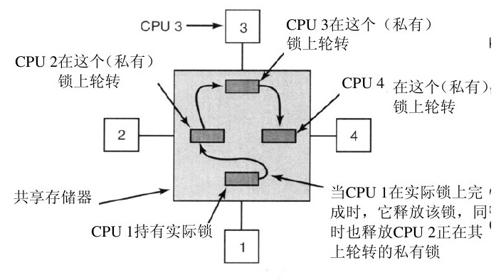
一个更好的思想是,让每个打算获得互斥信号量的CPU都拥有各自用于测试的私有锁变量,如图8-11所示(Mellor-Crummey和Scott,1991)。有关的变量应该存放在未使用的高速缓存块中以避免冲突。对这种算法的描述如下:给一个未能获得锁的CPU分配一个锁变量并且把它附在等待该锁的CPU链表的末端。在当前锁的持有者退出临界区时,它释放链表中的首个CPU正在测试的私有锁(在自己的高速缓存中)。然后该CPU进入临界区。操作完成之后,该CPU释放锁。其后继者接着使用,以此类推。尽管这个协议有些复杂(为了避免两个CPU同时把它们自己加在链表的末端),但它能够有效工作,而且消除了饥饿问题。具体细节,读者可以参考有关论文。
自旋与切换
到目前为止,不论是连续轮询方式、间歇轮询方式,还是把自己附在进行等候CPU链表中的方式,我们都假定需要加锁的互斥信号量的CPU只是保持等待。有时对于提出请求的CPU而言,只有等待,不存在其他替代的办法。例如,假设一些CPU是空闲的,需要访问共享的就绪链表(ready list)以便选择一个进程运行。如果就绪链表被锁住了,那么CPU就不能够只是决定暂停其正在进行的工作,而去运行另一个进程,因为这样做需要访问就绪链表。CPU必须保持等待直到能够访问该就绪链表。
然而,在另外一些情形中,却存在着别的选择。例如,如果在一个CPU中的某些线程需要访问文件系统缓冲区高速缓存,而该文件系统缓冲区高速缓存正好锁住了,那么CPU可以决定切换至另外一个线程而不是等待。有关是进行自旋还是进行线程切换的问题则是许多研究课题的内容,下面会讨论其中的一部分。请注意,这类问题在单处理机中是不存在的,因为没有另一个CPU释放锁,那么自旋就没有任何意义。如果一个线程试图取得锁并且失败,那么它总是被阻塞,这样锁的所有者有机会运行和释放该锁。
假设自旋和进行线程切换都是可行的选择,则可进行如下的权衡。自旋直接浪费了CPU周期。重复地测试锁并不是高效的工作。不过,切换也浪费了CPU周期,因为必须保存当前线程的状态,必须获得保护就绪链表的锁,还必须选择一个线程,必须装入其状态,并且使其开始运行。更进一步来说,该CPU高速缓存还将包含所有不合适的高速缓存块,因此在线程开始运行的时候会发生很多代价昂贵的高速缓存未命中。TLB的失效也是可能的。最后,会发生返回至原来线程的切换,随之而来的是更多的高速缓存未命中。花费在这两个线程间来回切换和所有高速缓存未命中的周期时间都浪费了。
如果预先知道互斥信号量通常被持有的时间,比如是50µs,而从当前线程切换需要1ms,稍后切换返回还需1ms,那么在互斥信号量上自旋则更为有效。另一方面,如果互斥信号量的平均保持时间是10ms,那就值得忍受线程切换的麻烦。问题在于,临界区在这个期间会发生相当大的变化,所以,哪一种方法更好些呢?
有一种设计是总是进行自旋。第二种设计方案则总是进行切换。而第三种设计方案是每当遇到一个锁住的互斥信号量时,就单独做出决定。在必须做出决定的时刻,并不知道自旋和切换哪一种方案更好,但是对于任何给定的系统,有可能对其所有的有关活动进行跟踪,并且随后进行离线分析。然后就可以确定哪个决定最好及在最好情形下所浪费的时间。这种事后算法(hindsight algorithm)成为对可行算法进行测量的基准评测标准。
已有研究人员对上述这一问题进行了研究(Karlin等人,1989;Karlin等人,1991;Ousterhout,1982)。多数的研究工作使用了这样一个模型:一个未能获得互斥信号量的线程自旋一段时间。如果时间超过某个阈值,则进行切换。在某些情形下,该阈值是一个定值,典型值是切换至另一个线程再切换回来的开销。在另一些情形下,该阈值是动态变化的,它取决于所观察到的等待互斥信号量的历史信息。
在系统跟踪若干最新的自旋时间并且假定当前的情形可能会同先前的情形类似时,就可以得到最好的结果。例如,假定还是1ms切换时间,线程自旋时间最长为2ms,但是要观察实际上自旋了多长时间。如果线程未能获取锁,并且发现在之前的三轮中,平均等待时间为200µs,那么,在切换之前就应该先自旋2ms。但是,如果发现在先前的每次尝试中,线程都自旋了整整2ms,则应该立即切换而不再自旋。更多的细节可以在(Karlin等人,1991)中找到。










