预计阅读本页时间:-

8.2 多计算机
多处理机流行和有吸引力的原因是,它们提供了一个简单的通信模型:所有CPU共享一个公用存储器。进程可以向存储器写消息,然后被其他进程读取。可以使用互斥信号量、信号量、管程(monitor)和其他适合的技术实现同步。惟一美中不足的是,大型多处理机构造困难,因而造价高昂。
为了解决这个问题,人们在多计算机(multicomputers)领域中进行了很多研究。多计算机是紧耦合CPU,不共享存储器。每台计算机有自己的存储器,如图8-1b所示。众所周知,这些系统有各种其他的名称,如机群计算机(cluster computers)以及工作站机群(Clusters of Workstations,COWS)。
多计算机容易构造,因为其基本部件只是一台配有高性能网络接口卡的PC裸机。当然,获得高性能的秘密是巧妙地设计互连网络以及接口卡。这个问题与在一台多处理机中构造共享存储器是完全类似的。但是,由于目标是在微秒(microsecond)数量级上发送消息,而不是在纳秒(nanosecond)数量级上访问存储器,所以这是一个相对简单、便宜且容易实现的任务。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
在下面几节中,我们将首先简要地介绍多计算机硬件,特别是互连硬件。然后,我们将讨论软件,从低层通信软件开始,接着是高层通信软件。我们还将讨论在没有共享存储器的系统中实现共享存储器的方法。最后,我们将讨论调度和负载平衡的问题。
8.2.1 多计算机硬件
一台多计算机的基本节点包括一个CPU、存储器、一个网络接口,有时还有一个硬盘。节点可以封装在标准的PC机箱中,不过通常没有图像适配卡、显示器、键盘和鼠标等。在某些情况下,PC机中有一块2通道或4通道的多处理机主板,可能带有双核或者四核芯片而不是单个CPU,不过为了简化问题,我们假设每个节点有一个CPU。通常成百个甚至上千个节点连接在一起组成一个多计算机。下面我们将介绍一些关于硬件如何组织的内容。
1.互连技术
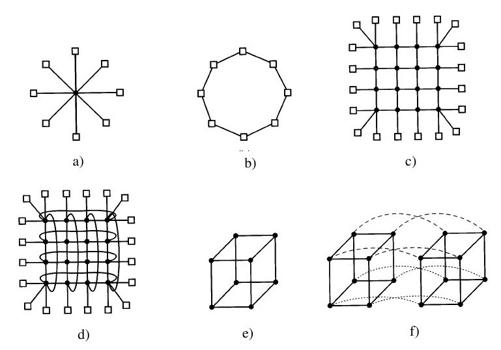
在每个节点上有一块网卡,带有一根或两根从网卡上接出的电缆(或光纤)。这些电缆或者连到其他的节点上,或者连到交换机上。在小型系统中,可能会有一个按照图8-16a的星型拓扑结构连接所有节点的的交换机。现代交换型以太网就采用了这种拓扑结构。
作为单一交换机设计的另一种选择,节点可以组成一个环,有两根线从网络接口卡上出来,一根去连接左面的节点,另一根去连接右面的节点,如图8-16b所示。在这种拓扑结构中不需要交换机,所以图中也没有。
图8-16c中的网格(grid或mesh)是一种在许多商业系统中应用的二维设计。它相当规整,而且容易扩展为大规模系统。这种系统有一个直径(diameter),即在任意两个节点之间的最长路径,并且该值只按照节点数目的平方根增加。网格的变种是双凸面(double torus),如图8-16d所示,这是一种边连通的网格。这种拓扑结构不仅较网格具有更强的容错能力而且其直径也比较小,因为对角之间的通信只需要两跳。
图8-16e中的立方体(cube)是一种规则的三维拓扑结构。我们展示的是2×2×2立方体,更一般的情形则是k×k×k立方体。在图8-16f中,是一种用两个三维立方体加上对应边连接所组成四维立方体。我们可以仿照图8-16f的结构并且连接对应的节点以组成四个立方体组块来制作五维立方体。为了实现六维,可以复制四个立方体的块并把对应节点互连起来,以此类推。以这种形式组成的n维立方体称为超立方体(hypercube)。许多并行计算机采用这种拓扑结构,因为其直径随着维数的增加线性增长。换句话说,直径是节点数的自然对数,例如,一个10维的超立方体有1024个节点,但是其直径仅为10,有着出色的延迟特性。注意,与之相反的是,1024的节点如果按照32×32网格布局则其直径为62,较超立方体相差了六倍多。对于超立方体而言,获得较小直径的代价是扇出数量(fanout)以及由此而来的连接数量(及成本)的大量增加。
在多计算机中可采用两种交换机制。在第一种机制里,每个消息首先被分解(由用户软件或网络接口进行)成为有最大长度限制的块,称为包(packet)。该交换机制称为存储转发包交换(store-and-forward packet switching),由源节点的网络接口卡注入到第一个交换机的包组成,如图8-17a所示。比特串一次进来一位,当整个包到达一个输入缓冲区时,它被复制到沿着其路径通向下一个交换机的队列当中,如图8-17b所示。当包到达目标节点所连接的交换机时,如图8-17c所示,该包被复制进入目标节点的网络接口卡,并最终到达其RAM。
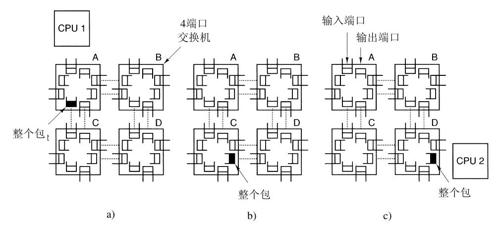
尽管存储转发包交换灵活且有效,但是它存在通过互连网络时增加时延(延迟)的问题。假设在图8-17中把一个包传送一跳所花费的时间为T纳秒。为了从CPU 1到CPU 2,该包必须被复制四次(至A、至C、至D以及到目标CPU),而且在前一个包完成之前,不能开始有关的复制,所以通过该互连网络的时延是4T。一条出路是设计一个网络,其中的包可以逻辑地划分为更小的单元。只要第一个单元到达一个交换机,它就被转发到下一个交换机,甚至可以在包的结尾到达之前进行。可以想象,这个传送单元可以小到1比特。
另一种交换机制是电路交换(circuit switching),它包括由第一个交换机建立的,通过所有交换机而到达目标交换机的一条路径。一旦该路径建立起来,比特流就从源到目的地通过整个路径不断地尽快输送。在所涉及的交换机中,没有中间缓冲。电路交换需要有一个建立阶段,它需要一点时间,但是一旦建立完成,速度就很快。在包发送完毕之后,该路径必须被拆除。电路交换的一种变种称为虫孔路由(wormhole routing),它把每个包拆成子包,并允许第一个子包在整个路径还没有完全建立之前就开始流动。
2.网络接口
在多计算机中,所有节点里都有一块插卡板,它包含节点与互连网络的连接,这使得多计算机连成一体。这些板的构造方式以及它们如何同主CPU和RAM连接对操作系统有重要影响。这里简要地介绍一些有关的内容。部分内容来源于(Bhoedjang,2000)。
事实上在所有的多计算机中,接口板上都有一些用来存储进出包的RAM。通常,在包被传送到第一个交换机之前,这个要送出的包必须被复制到接口板的RAM中。这样设计的原因是许多互连网络是同步的,所以一旦一个包的传送开始,比特流必须以恒定的速率连续进行。如果包在主RAM中,由于内存总线上有其他的信息流,所以这个送到网络上的连续流是不能保证的。在接口板上使用专门的RAM,就消除了这个问题。这种设计如图8-18所示。
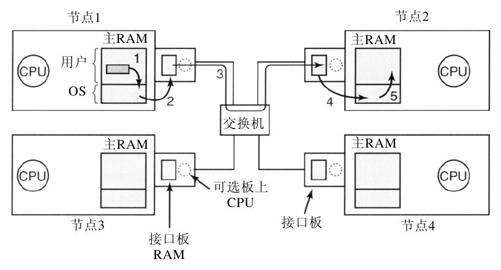
同样的问题还出现在接收进来的包上。从网络上到达的比特流速率是恒定的,并且经常有非常高的速率。如果网络接口卡不能在它们到达的时候实时存储它们,数据将会丢失。同样,在这里试图通过系统总线(例如PCI总线)到达主RAM是非常危险的。由于网卡通常插在PCI总线上,这是一个惟一的通向主RAM的连接,所以不可避免地要同磁盘以及每个其他的I/O设备竞争总线。而把进来的包首先保存在接口板的私有RAM中,然后再把它们复制到主RAM中,则更安全些。
接口板上可以有一个或多个DMA通道,甚至在板上有一个完整的CPU(乃至多个CPU)。通过请求在系统总线上的块传送(block transfer),DMA通道可以在接口板和主RAM之间以非常高的速率复制包,因而可以一次性传送若干字而不需要为每个字分别请求总线。不过,准确地说,正是这种块传送(它占用了系统总线的多个总线周期)使接口板上的RAM的需要是第一位的。
很多接口板上有一个完整的CPU,可能另外还有一个或多个DMA通道。它们被称为网络处理器(network processor),并且其功能日趋强大。这种设计意味着主CPU将一些工作分给了网卡,诸如处理可靠的传送(如果底层的硬件会丢包)、多播(将包发送到多于一个的目的地)、压缩/解压缩、加密/解密以及在多进程系统中处理安全事务等。但是,有两个CPU则意味着它们必须同步,以避免竞争条件的发生,这将增加额外的开销,并且对于操作系统来说意味着要承担更多的工作。










