预计阅读本页时间:-

1.6 系统调用
我们已经看到操作系统具有两种功能:为用户程序提供抽象和管理计算机资源。在多数情形下,用户程序和操作系统之间的交互处理的是前者,例如,创建、写入、读出和删除文件。对用户而言,资源管理部分主要是透明和自动完成的。这样,用户程序和操作系统之间的交互主要就是处理抽象。为了真正理解操作系统的行为,我们必须仔细地分析这个接口。接口中所提供的调用随着操作系统的不同而变化(尽管基于的概念是类似的)。
这样我们不得不在如下的可能方式中进行选择:(1)含混不清的一般性叙述(“操作系统提供读取文件的系统调用”);(2)某个特定的系统(“UNIX提供一个有三个参数的read系统调用:一个参数指定文件,一个说明数据应存放的位置,另一个说明应读出多少个字节”)。
我们选择后一种方式。这种方式需要更多的努力,但是它能更多地洞察操作系统具体在做什么。尽管这样的讨论会涉及专门的POSIX(International Standard 9945-1),以及UNIX、System V、BSD、Linux、MINIX3等,但是多数现代操作系统都有实现相同功能的系统调用,尽管它们在细节上差别很大。由于引发系统调用的实际机制是非常依赖于机器的,而且必须用汇编代码表达,所以,通过提供过程库使C程序中能够使用系统调用,当然也包括其他语言。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
记住下列事项是有益的。任何单CPU计算机一次只能执行一条指令。如果一个进程正在用户态中运行一个用户程序,并且需要一个系统服务,比如从一个文件读数据,那么它就必须执行一个陷阱或系统调用指令,将控制转移到操作系统。操作系统接着通过参数检查,找出所需要的调用进程。然后,它执行系统调用,并把控制返回给在系统调用后面跟随着的指令。在某种意义上,进行系统调用就像进行一个特殊的过程调用,但是只有系统调用可以进入内核,而过程调用则不能。
为了使系统调用机制更清晰,让我们简要地考察read系统调用。如上所述,它有三个参数:第一个参数指定文件,第二个指向缓冲区,第三个说明要读出的字节数。几乎与所有的系统调用一样,它的调用由C程序完成,方法是调用一个与该系统调用名称相同的库过程:read。由C程序进行的调用可有如下形式:
count=read(fd,buffer,nbytes);
系统调用(以及库过程)在count中返回实际读出的字节数。这个值通常和nbytes相同,但也可能更小,例如,如果在读过程中遇到了文件尾的情形就是如此。
如果系统调用不能执行,不论是因为无效的参数还是磁盘错误,count都会被置为-1,而在全局变量errno中放入错误号。程序应该经常检查系统调用的结果,以了解是否出错。
系统调用是通过一系列的步骤实现的。为了更清楚地说明这个概念,考察上面的read调用。在准备调用这个实际用来进行read系统调用的read库过程时,调用程序首先把参数压进堆栈,如图1-17中步骤1~步骤3所示。
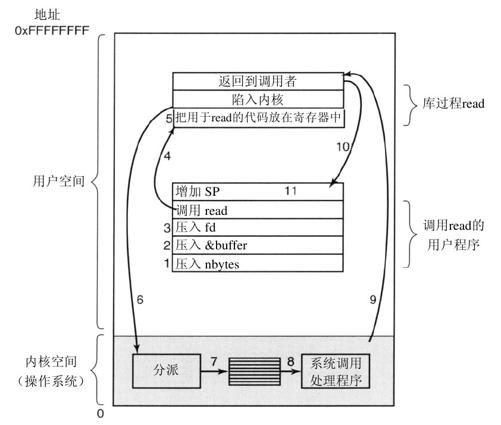
由于历史的原因,C以及C++编译器使用逆序(必须把第一个参数赋给printf(格式字串),放在堆栈的顶部)。第一个和第三个参数是值调用,但是第二个参数通过引用传递,即传递的是缓冲区的地址(由&指示),而不是缓冲区的内容。接着是对库过程的实际调用(第4步)。这个指令是用来调用所有过程的正常过程调用指令。
在可能是由汇编语言写成的库过程中,一般把系统调用的编号放在操作系统所期望的地方,如寄存器中(第5步)。然后执行一个TRAP指令,将用户态切换到内核态,并在内核中的一个固定地址开始执行(第6步)。TRAP指令实际上与过程调用指令相当类似,它们后面都跟随一个来自远地位置的指令,以及供以后使用的一个保存在栈中的返回地址。
然而,TRAP指令与过程指令存在两个方面的差别。首先,它的副作用是,切换到内核态。而过程调用指令并不改变模式。其次,不像给定过程所在的相对或绝对地址那样,TRAP指令不能跳转到任意地址上。根据机器的体系结构,或者跳转到一个单固定地址上,或者指令中有一8位长的字段,它给定了内存中一张表格的索引,这张表格中含有跳转地址。
跟随在TRAP指令后的内核代码开始检查系统调用编号,然后发出正确的系统调用处理命令,这通常是通过一张由系统调用编号所引用的、指向系统调用处理器的指针表来完成(第7步)。此时,系统调用句柄运行(第8步)。一旦系统调用句柄完成其工作,控制可能会在跟随TRAP指令后面的指令中返回给用户空间库过程(第9步)。这个过程接着以通常的过程调用返回的方式,返回到用户程序(第10步)。
为了完成整个工作,用户程序还必须清除堆栈,如同它在进行任何过程调用之后一样(第11步)。假设堆栈向下增长,如经常所做的那样,编译后的代码准确地增加堆栈指针值,以便清除调用read之前压入的参数。在这之后,原来的程序就可以随意执行了。
在前面第9步中,我们提到“控制可能会在跟随TRAP指令后面的指令中返回给用户空间库过程”,这是有原因的。系统调用可能堵塞调用者,避免它继续执行。例如,如果试图读键盘,但是并没有任何键入,那么调用者就必须被阻塞。在这种情形下,操作系统会查看是否有其他可以运行的进程。稍后,当需要的输入出现时,进程会提醒系统注意,然后步骤9~步骤11会接着进行。
下面几节中,我们将考察一些常用的POSIX系统调用,或者用更专业的说法,考察进行这些系统调用的库过程。POSIX大约有100个过程调用,它们中最重要的过程调用列在图1-18中。为方便起见,它们被分成4类。我们用文字简要地叙述其作用。
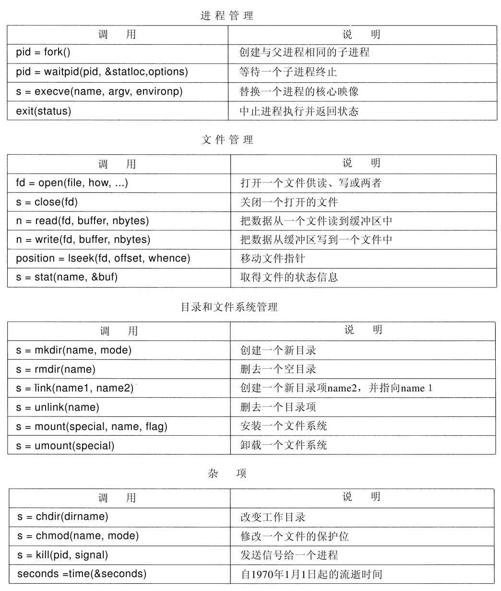
从广义上看,由这些调用所提供的服务确定了多数操作系统应该具有的功能,而在个人计算机上,资源管理功能是较弱的(至少与多用户的大型机相比较是这样)。所包含的服务有创建与终止进程,创建、删除、读出和写入文件,目录管理以及完成输入输出。
有必要指出,将POSIX过程映射到系统调用并不是一对一的。POSIX标准定义了构造系统所必须提供的一套过程,但是并没有规定它们是系统调用,是库调用还是其他的形式。如果不通过系统调用就可以执行一个过程(即无须陷入内核),那么从性能方面考虑,它通常会在用户空间中完成。不过,多数POSIX过程确实进行系统调用,通常是一个过程直接映射到一个系统调用上。在有一些情形下,特别是所需要的过程仅仅是某个调用的变体时,此时一个系统调用会对应若干个库调用。
1.6.1 用于进程管理的系统调用
在图1-18中的第一组调用处理进程管理。将有关fork(派生)的讨论作为本节的开始是较为合适的。在UNIX中,fork是惟一可以在POSIX创建进程的途径。它创建一个原有进程的精确副本,包括所有的文件描述符,寄存器等全部内容。在fork之后,原有的进程及其副本(父与子)就分开了。在fork时,所有的变量具有一样的值,虽然父进程的数据被复制用以创建子进程,但是其中一个的后续变化并不会影响到另一个。(由父进程和子进程共享的程序正文,是不可改变的。)fork调用返回一个值,在子进程中该值为零,并且等于子进程的进程标识符,或等于父进程中的PID。使用被返回的PID,就可以在两个进程中看出哪一个是父进程,哪一个是子进程。
多数情形下,在fork之后,子进程需要执行与父进程不同的代码。这里考虑shell的情形。它从终端读取命令,创建一个子进程,等待该子进程执行命令,在该子进程终止时,读入下一条命令。为了等待子进程结束,父进程执行一个waitpid系统调用,它只是等待,直至子进程终止(若有多个子进程存在的话,则直至任何一个子进程终止)。waitpid可以等待一个特定的子进程,或者通过将第一个参数设为-1的方式,从而等待任何一个老的子进程。在waitpid完成之后,将把第二个参数statloc所指向的地址设置为子进程的退出状态(正常或异常终止以及退出值)。有各种可使用的选项,它们由第三个参数确定。
现在考虑shell如何使用fork。在键入一条命令后,shell创建一个新的进程。这个子进程必须执行用户的命令。通过使用execve系统调用可以实现这一点,这个系统调用会引起其整个核心映像被一个文件所替代,该文件由第一个参数给定。(实际上,该系统调用自身是exec系统调用,但是若干个不同的库过程使用不同的参数和稍有差别的名称调用该系统调用。在这里,我们都把它们视为系统调用。)在图1-19中,用一个高度简化的shell说明fork、waitpid以及execve的使用。

在最一般情形下,execve有三个参数:将要执行的文件名称,一个指向变量数组的指针,以及一个指向环境数组的指针。这里对这些参数做一个简要的说明。各种库例程,包括execl、execv、execle以及execve,可以允许略掉参数或以各种不同的方式给定。在本书中,我们在所有涉及的地方使用exec描述系统调用。
下面考虑诸如
cp file1 file2
的命令,该命令将file1复制到file2。在shell创建进程之后,该子进程定位和执行文件cp,并将源文件名和目标文件名传递给它。
cp主程序(以及多数其他C程序的主程序)都有声明
main(argc,argv,envp)
其中argc是该命令行内有关参数数目的计数器,包括程序名称。例如,上面的例子中,argc为3。
第二个参数argv是一个指向数组的指针。该数组的元素i是指向该命令行第i个字串的指针。在本例中,argv[0]指向字串“cp”,argv[1]指向字符串“file1”,argv[2]指向字符串“file2”。
main的第三个参数envp指向环境的一个指针,该环境是一个数组,含有name=value的赋值形式,用以将诸如终端类型以及根目录等信息传送给程序。还有供程序可以调用的库过程,用来取得环境变量,这些变量通常用来确定用户希望如何完成特定的任务(例如,使用默认打印机)。在图1-19中,没有环境参数传递给子进程,所以execve的第三个参数为零。
如果读者认为exec过于复杂,那么也不要失望。这是在POSIX的全部(语义上)系统调用中最复杂的一个,其他的都非常简单。作为一个简单例子,考虑exit,这是在进程完成执行后应执行的系统调用。这个系统调用有一个参数,退出状态(0至255),该参数通过waitpid系统调用中的statloc返回给父进程。
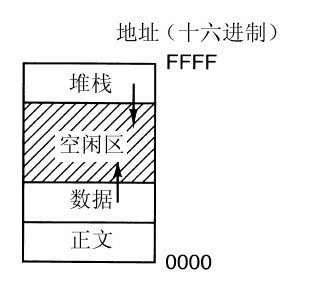
在UNIX中的进程将其存储空间划分为三段:正文段(如程序代码)、数据段(如变量)以及堆栈段。数据段向上增长而堆栈向下增长,如图1-20所示。夹在中间的是未使用的地址空间。堆栈在需要时自动地向中间增长,不过数据段的扩展是显式地通过系统调用brk进行的,在数据段扩充后,该系统调用指定一个新地址。但是,这个调用不是POSIX标准中定义的调用,对于存储器的动态分配,我们鼓励程序员使用malloc库过程,而malloc的内部实现则不是一个适合标准化的主题,因为几乎没有程序员直接使用它,我们有理由怀疑,会有什么人注意到brk实际不是属于POSIX的。