预计阅读本页时间:-

11.8.2 NTFS文件系统的实现
NTFS文件系统是专门为NT系统开发的,用来替代OS/2中的HPFS文件系统的。它是一个具有很高复杂性和精密性的文件系统。NT系统的大部分是在陆地上设计的。从这方面看,NTFS与NT系统其他部分相比是独一无二的,因为它的很多最初设计都是在一艘驶出普吉特湾的帆船的甲板上完成的(严格遵守上午工作,下午喝啤酒的作息协议)。
接下来,我们将从NTFS结构开始,探讨一系列NTFS特性,包括文件名查找、文件压缩、日志和加密。
1.文件系统结构
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
每个NTFS卷(如磁盘分区)都包含文件、目录、位图和其他数据结构。每个卷被组织成磁盘块的一个线形序列(在微软的术语中叫“簇”),每个卷中块的大小是固定的。根据卷的大小不同,块的大小从512字节到64KB不等。大多数NTFS磁盘使用4KB的块,作为有利于高效传输的大块和有利于减少内部碎片的小块之间的折中办法。每个块用其相对于卷起始位置的64位偏移量来指示。
每个卷中的主要数据结构叫MFT(主文件表,Master File Table),该表是以1KB为固定大小的记录的线形序列。每个MFT记录描述一个文件或目录。它包含了如文件名、时间戳、文件中的块在磁盘上的地址的列表等文件属性。如果一个文件非常大,有时候会需要两个或更多的MFT记录来保存所有块的地址列表。这时,第一个MFT记录叫做基本记录(base record),该记录指向其他的MFT记录。这种溢出方案可以追溯到CP/M,那时每个目录项称为一个范围(extent)。用一个位图记录哪个MFT表项是空闲的。
MFT本身就是一个文件,可以被放在卷中的任何位置,这样就避免了在第一磁道上出现错误扇区引起的问题。而且MFT可以根据需要变大,最大可以有248 个记录。
图11-41是一个MFT。每个MFT记录由数据对(属性头,值)的一个序列组成。每个属性由一个说明了该属性是什么和属性值有多长的头开始。一些属性值是变长的,如文件名和数据。如果属性值足够短能够放到MFT记录中,那么就把它放到记录里。这叫做直接文件(immediate file,[Mullender and Tanenbaum,1984])。如果属性值太长,它将被放在磁盘的其他位置,并在MFT记录里存放一个指向它的指针。这使得NTFS对于小的域(即那些能够放入MFT记录中的域)非常有效率。
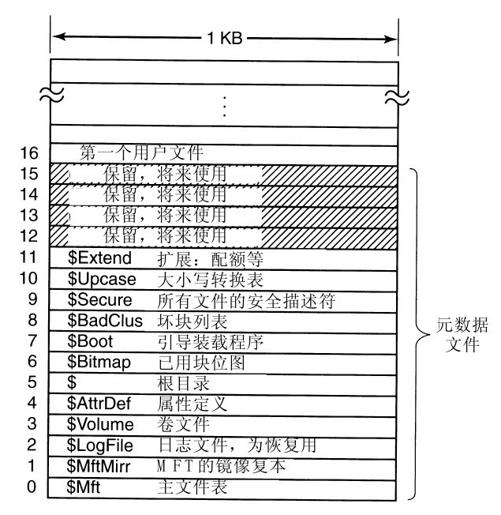
最开始的16个MFT记录为NTFS元数据文件而预留,如图11-41所示。每一个记录描述了一个正常的具有属性和数据块的文件,就如同其他文件一样。这些文件中每一个都由“$”开始表明它是一个元数据文件。第一个记录描述了MFT文件本身。它说明了MFT文件的块都放在哪里以确保系统能找到MFT文件。很明显,Windows需要一个方法找到MFT文件中第一个块,以便找到其余的文件系统信息。找到MFT文件中第一个块的方法是查看启动块,那是卷被格式化为文件系统时地址所存放的位置。
记录1是MFT文件早期部分的复制。这部分信息非常重要,因此拥有第二份拷贝至关重要以防MFT的第一块坏掉。记录2是一个Log文件。当对文件系统做结构性的改变时,例如,增加一个新目录或删除一个现有目录,动作在执行前就记录在Log里,从而增加在这个动作执行时出错后(比如一次系统崩溃)被正确恢复的机会。对文件属性做的改变也会记录在这里。事实上,唯一不会记录的改变是对用户数据的改变。记录3包含了卷的信息,比如大小、卷标和版本。
上面提到,每个MFT记录包含一个(属性头,值)数据对的序列。属性在$AttrDef文件中定义。这个文件的信息在MFT记录4里。接下来是根目录,根目录本身是一个文件并且可以变为任意长度。MFT记录5用来描述根目录。
卷里的空余空间通过一个位图来跟踪。这个位图本身是一个文件,它的磁盘地址和属性由MFT记录6给出。下一个MFT记录指向引导装载程序。记录8用来把所有的坏块链接在一起来确保不会有文件使用它们。记录9包含安全信息。记录10用于大小写映射。对于拉丁字母A-Z,映射是非常明确的(至少是对说拉丁语的人来说)。对于其他语言的映射,如希腊、亚美尼亚或乔治亚,就对于讲拉丁语的人不太明确,因此这个文件告诉我们如何做。最后,记录11是一个目录包含杂项文件用于磁盘配额、对象标识符、再解析点,等等。最后四个MFT记录被留作将来使用。
每个MFT记录由一个记录头和后面跟着的(属性头,值)对组成。记录头包含一个幻数用于有效性检查,一个序列号(每次当记录被一个新文件再使用时就被更新),文件引用记数,记录实际使用的字节数,基本记录(仅用于扩展记录)的标识符(索引,序列号),和其他一些杂项。
NTFS定义了13个属性能够出现在MFT记录中。图11-42列出了这些属性。每个属性头标识了属性,给出了长度,值字段的位置,一些各种各样的标记和其他信息。通常,属性值直接跟在它们的属性头后面,但是如果一个值对于一个MFT记录太长的话,它可能被放在不同的磁盘块中。这样的属性称作非常驻属性,数据属性很明显就是这样一个属性。一些属性,像名字,可能出现重复,但是所有属性必须在MFT记录中按照固定顺序出现。常驻属性头有24个字节长;非常驻属性头会更长,因为它们包含关于在磁盘上哪些位置能找到这些属性的信息。
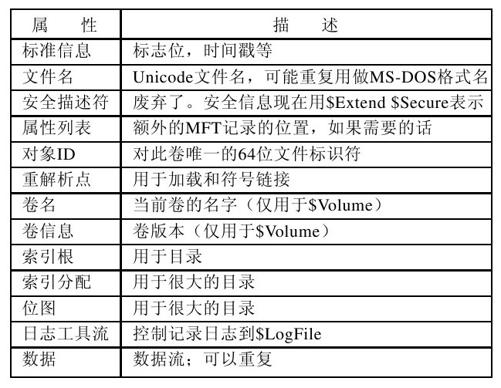
标准的信息域包含文件所有者、安全信息、POSIX需要的时间戳、硬连接计数、只读和存档位,等等。这些域是固定长度的,并且总是存在的。文件名是一个可变长度Unicode编码的字符串。为了使具有非MS-DOS文件名的文件可以访问老的16位程序,文件也可以有一个符合8+3规则的MS-DOS短名字。如果实际文件名符合8+3命名规则,第二个MS-DOS文件名就不需要了。
在NT4.0中,安全信息被放在一个属性中,但在Windows 2000及以后的版本中,安全信息全部都放在一个单独的文件中使得多个文件可以共享相同的安全描述。由于安全信息对于每个用户的许多文件来说是相同的,于是这使得许多MFT记录和整个文件系统节省了大量的空间。
当属性不能全部放在MFT记录中时,就需要使用属性列表。这个属性就会说明在哪里找到扩展记录。列表中的每个条目在MFT中包含一个48位的索引来说明扩展记录在哪里,还包含一个16位的序号来验证扩展记录与基本记录是否匹配。
就像UNIX文件拥有一个I节点号一样,NTFS文件也有一个ID。文件可以依据ID被打开,但是由于ID是基于MFT记录的,并且可以因该文件的记录移动(例如,如果文件因备份被恢复)而改变,所以当ID必须保持不变时,这个NTFS分配的ID并不总是有用。NTFS允许有一个可以设置在文件上而且永远不需要改变的独立对象ID属性。举例来说,当一个文件被拷贝到一个新卷时,这个属性随着文件一起过去。
重解析点告诉分析文件名的过程来做特别的事。这个机制用于显式加载文件系统和符号链接。两个卷属性用于标示卷。随后三个属性处理如何实现目录——小的目录就是文件列表,大的目录使用B+树实现。日志工具流属性用来加密文件系统。
最后,我们关注最重要的属性:数据流(在一些情况下叫流)。一个NTFS文件有一个或多个数据流,这些就是负载所在。默认数据流是未命名的(例如,目录路径\文件名:$DATA),但是替代数据流有自己的名字,例如:目录路径\文件名:流名:$DATA。
对于每个流,流的名字(如果有)会在属性头中。头后面要么是说明了流包含哪些块的磁盘地址列表,要么是仅几百字节大小的流(有许多这样的流)本身。存储了实际流数据的MFT记录称为立即文件(Mullender和Tanenbaum,1984)。
当然,大多数情况下,数据放不进一个MFT记录中,因此这个属性通常是非常驻属性。现在让我们看一看NTFS如何记录特殊数据中非常驻属性的位置。
2.存储分配
保持对磁盘中在可能的情况下,连续分配的块进行跟踪的模型,这是出于效率的原因。举例来说,如果一个流的第一个逻辑块放在磁盘上的块20,那么系统将努力把第二个逻辑块放在块21,第三个逻辑块放在块22,以此类推,实现这些行串的一个方法是尽可能一次分配许多磁盘块。
一个流中的块是通过一串记录描述的,每个记录描述了一串逻辑上连续的块,对于一个没有孔的流来说,只有唯一的一个记录。按从头到尾的顺序写的流都属于这一类。对于一个包含一个孔的流(例如,只有块0~49和块60~79被定义了),会有两个记录。这样的流会产生于先写入前50个块,然后找到逻辑上第60块,然后写其他20个块。当孔被读出时,用全零表示。有孔的文件称为稀疏文件。
每个记录始于一个头,这个头给出第一个块在流中偏移量。接着是没有被记录覆盖的第一个块的偏移量。在上面的例子中,第一个记录有一个(0,50)的头,并会提供这50个块的磁盘地址。第二个记录有一个(60,80)的头,会提供其他20个块的磁盘地址。
每个记录的头后面跟着一个或多个对,每个对给出了磁盘地址和持续长度。磁盘地址是该磁盘块离本分区起点的偏移量;游程在行串中块的数量。在一段行串记录中需要有多少对就可以有多少对。图11-43描述了用这种方式表示的三段、9块的流。
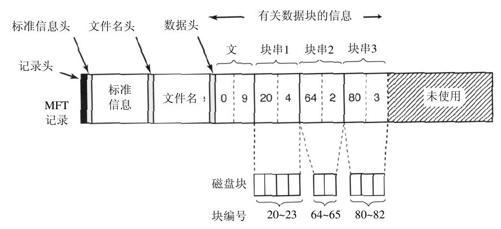
在这个图中,有一个9个块(头,0~8)的短流的MFT记录。它由磁盘上三个行串的连续块组成。第一段是块20~23,第二段是块64~65,第三段是80~82。每一个行串被记录在MFT记录中的一个(磁盘地址,块计数)对中。有多少行串是依赖于当流被创建时磁盘块分配器在找连续块的行串时做的有多好。对于一个n块的流,段数可能是从l到n的任意值。
有必要在这里做几点说明:
首先,用这种方法表达的流的大小没有上限限制。在地址不压缩的情况下,每一对需要两个64位数表示,总共16字节。然而,一对能够表示100万个甚至更多的连续的磁盘空间。实际上,20M的流包含20个独立的包含100万个1KB的块的行串,每个都可以轻易地放在一个MFT记录中,然而一个60KB的被分散到60个不同的块的流却不行。
其次,表示每一对的直截了当的方法会占用2×8个字节,有压缩方法可以把一对的大减小到低于16字节。许多磁盘地址有多个高位0字节。这些可以被忽略。数据头能告诉我们有多少个高位0字节被忽略了,也就是说,在一个地址中实际上有多少个字节被用。也可以用其他的压缩方式。实际上,一对经常只有4个字节。
第一个例子是比较容易的:所有的文件信息能容纳在一个MFT记录中,如果文件比较大或者是高度碎片化以至于信息不能放在一个MFT记录当中,这时会发生什么呢?答案很简单:用两个或更多的MFT记录。从图11-44可以看出,一个文件的首MFT记录是102,对于一个MFT记录而言它有太多的行串,因而它会计算需要多少个扩展的MFT记录。比如说两个,于是会把它们的索引放到首记录中,首记录剩余的空间用来放前k个行串。
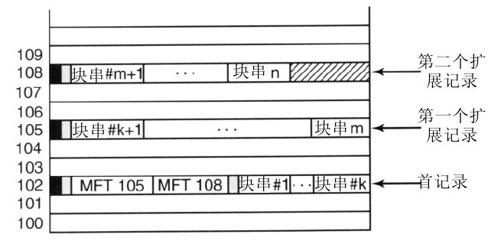
注意,图11-44包含了一些多余的信息。理论上不需要指出一串行串的结尾,因为这些信息可以从行串对中计算出来。列出这些信息是为了更有效地搜索:找到在一个给定文件偏移量的块,只需要去检查记录头,而不是行串对。
当MFT记录102中所有的空间被用完后,剩余的行串继续在MFT记录105中存放,并在这个记录中放入尽可能多的项。当这个记录也用完后,剩下的行串放在MFT记录108中。这种方式可以用多个MFT记录去处理大的分段存储文件。
有可能会出现这样的问题:如果文件需要的MFT记录太多,以至于首个MTF记录中没有足够的空间去存放所有的索引。解决这个问题的方法是:使扩展的MFT记录列表成为非驻留的(即:存放在其他的硬盘区域而不是在首MFT记录中),这样它就能根据需要而增大。
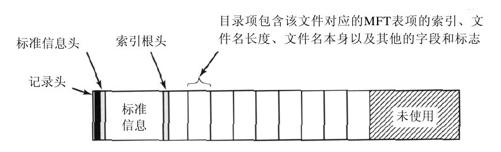
图11-45表示一个MFT表项如何描述一个小目录。这个记录包含若干目录项,每一个目录项可以描述一个文件或目录。每个表项包含一个定长的结构体和紧随其后的不定长的文件名。定长结构体包含该文件对应的MFT表项的索引、文件名长度以及其他的属性和标志。在目录中查找一个目录项需要依次检查所有的文件名。
大目录采用一种不同的格式,即用B+树而不是线性结构来列出文件。通过B+树可以按照字母顺序查找文件,并且更容易在目录的正确位置插入新的文件名。
现在有足够的信息去描述使用文件名对文件\??\C:\foo\bar的查找是如何进行的。从图11-22可以知道Win32、原生NT系统调用、对象和I/O管理器如何协作通过向C盘的NTFS设备栈(device stack)发送I/O请求打开一个文件。I/O请求要求NTFS为剩余的路径名\foo\bar填写一个文件对象。
NTFS从C盘根目录开始分析\foo\bar路径,C盘的块可以在MFT中的第五个表项中找到(参考图11-41)。然后在根目录中查找字符串“foo”,返回目录foo在MFT中的索引,接着再查找字符串“bar”,得到这个文件的MFT记录的引用。NTFS通过调用安全引用管理器来实施访问检查,如果所有的检查都通过了,NTFS从MFT记录中搜索得到::$DATA属性,即默认的数据流。
找到文件bar后,NTFS在I/O管理器返回的文件对象上设置指针指向它自己的元数据。元数据包括指向MFT记录的指针、压缩和范围锁、各种关于共享的细节等。大多数元数据包含在一些数据结构中,这些数据结构被所有引用这个文件的文件对象共享。有一些域是当前打开的文件特有的,比如当这个文件被关闭时是否需要删除。一旦文件成功打开,NTFS调用IoCompleteRequest,它通过把IPR沿I/O栈向上传递给I/O和对象管理器。最终,这个文件对象的句柄被放进当前进程的句柄表中,然后回到用户态。之后调用ReadFile时,应用程序能够提供句柄,该句柄表明C:\foo\bar文件对象应该包含在传递到C:设备栈给NTFS的读请求中。
除了支持普通文件和目录外,NTFS支持像UNIX那样的硬连接,也通过一个叫做重解析点的机制支持符号链接。NTFS支持把一个文件或者目录标记为一个重解析点,并将其和一块数据关联起来。当在文件名解析的过程中遇到这个文件或目录时,操作就会失败,这块数据被返回到对象管理器。对象管理器将这块数据解释为另一个路径名,然后更新需要解析的字符串,并重启I/O操作。这种机制用来支持符号链接和挂载文件系统,把文件搜索重定向到目录层次结构的另外一个部分甚至到另外一个不同的分区。
重解析点也用来为文件系统过滤器驱动程序而标记个别文件。在图11-22中显示了文件系统过滤器如何安装到I/O管理器和文件系统之间。I/O请求通过调用IoCompleteRequest来完成,其把控制权转交给在请求发起时设备栈上每个驱动程序插入到IRP中的完成例程。需要标记一个文件的驱动程序首先关联一个重解析标签,然后监控由于遇到重解析点而失败的打开文件操作的完成请求。通过用IRP传回的数据块,驱动程序可以判断出这是否是一个驱动程序自身关联到该文件的数据块。如果是,驱动程序将停止处理完成例程而接着处理原来的I/O请求。通常这将引发一个打开请求,但这时将有一个标志告诉NTFS忽略重解析点并同时打开文件。
3.文件压缩
NTFS支持透明的文件压缩。一个文件能够以压缩方式创建,这意味着当向磁盘中写入数据块时NTFS会自动尝试去压缩这些数据块,当这些数据块被读取时NTFS会自动解压。读或写的进程完全不知道压缩和解压在进行。
压缩流程是这样的:当NTFS写一个有压缩标志的文件到磁盘时,它检查这个文件的前16个逻辑块,而不管它们占用多少个项,然后对它们运行压缩算法,如果压缩后的数据能够存放在15个甚至更少的块中,压缩数据将写到硬盘中;如果可能的话,这些块在一个行串里。如果压缩后的数据仍然占用16个块,这16个块以不压缩方式写到硬盘中。之后,去检查第16-31块看是否能压缩到15个甚至更少的块,以此类推。
图11-46a显示一个文件。该文件的前16块被成功地压缩到了8个,对第二个16块的压缩没有成功,第三个16块也压缩了50%。这三个部分作为三个行串来写,并存储于MFT记录中。“丢失”的块用磁盘地址0存放在MFT表项中,如图11-46b所示。在图中,头(0,48)后面有五个二元组,其中,两个对应着第一个(被压缩)行串,一个对应没有压缩的行串,两个对应最后一个(被压缩)行串。
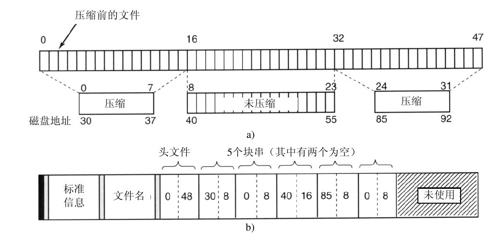
当读文件时,NTFS需要分辨某个行串是否被压缩过,它可以根据磁盘地址进行分辨,如果其磁盘地址是0,表明它是16个被压缩的块的最后部分。为了避免混淆,磁盘第0块不用于存储数据。同时,因为卷上的第0块包含了引导扇区,用它来存储数据也是不可能的。
随机访问压缩文件也是可行的,但是需要技巧。假设一个进程寻找图11-46中文件的第35块,NTFS是如何定位一个压缩文件的第35块区的呢?答案是NTFS必须首先读取并且解压整个行串,获得第35块的位置,之后就可以将该块传给读取它的进程。选择16个块作为压缩单元是一个折衷的结果,短了会影响压缩效率,长了则会使随机访问开销过大。
4.日志
NTFS支持两种让程序探测卷上文件和目录变化的机制。第一种机制是调用名为NtNotifyChange Directory File的I/O操作,传递一个缓冲区给系统,当系统探测到目录或者子目录树变化时,该操作返回。这个I/O操作的结果是在缓冲区里填上变化记录的一个列表。缓冲区应该足够大,否则填不下的记录会被丢弃。
第二种机制是NTFS变化日志。NTFS将卷上的目录和文件的变化记录保存到一个特殊文件中,程序可以使用特殊文件系统控制操作来读取,即调用API NtFsControlFile并以FSCTL_QUERY_USN_JOURNAL为参数。日志文件通常很大,而且日志中的项在被检查之前重用的可能性非常小。
5.文件加密
如今,计算机用来存储很多敏感数据,包括公司收购计划、税务信息、情书,数据的所有者不想把这些信息暴露给任何人。但是信息的泄漏是有可能发生的,例如笔记本电脑的丢失或失窃;使用MS-DOS软盘重起桌面系统来绕过Windows的安全保护;或者将硬盘从计算机里移到另一台安装了不安全操作系统的计算机中。
Windows提供了加密文件的选项来解决这些问题,因此当电脑的失窃或用MS-DOS重启时,文件内容是不可读的。Windows加密的通常方式是将重要目录标识为加密的,然后目录里的所有文件都会被加密,新创建或移动到这些目录来的文件也会被加密。加密和解密不是NTFS自己管理的,而是由EFS(Encryption File System)驱动程序来管理,EFS作为回调向NTFS注册。
EFS为特殊文件和目录提供加密。在Windows Vista中还有另外一个叫做BitLocker的加密工具,它加密了卷上几乎所有的数据。只要用户使用强密钥来发挥这种机制的优势,任何情况下它都能帮助用户保护数据。考虑到系统丢失或失窃的数量,以及身份泄露的强烈敏感性,确保机密被保护是非常重要的。每天都有惊人数量的笔记本电脑丢失;仅考虑纽约市,华尔街大部分公司平均一周在出租车上丢失一台笔记本电脑。










