预计阅读本页时间:-

13.3.8 实用技术
我们刚刚了解了系统设计与实现的某些抽象思想,现在将针对系统实现考察一些有用的具体技术。这方面的技术很多,但是篇幅的限制使我们只能介绍其中的少数技术。
1.隐藏硬件
许多硬件是十分麻烦的,所以只好尽早将其隐藏起来(除非它要展现能力,而大多数硬件不会这样)。某些非常低层的细节可以通过如图13-2所示的HAL类型的层次得到隐藏。然而,许多硬件细节不能以这样的方式来隐藏。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
值得尽早关注的一件事情是如何处理中断。中断使得程序设计令人不愉快,但是操作系统必须对它们进行处理。一种方法是立刻将中断转变成别的东西,例如,每个中断都可以转变成即时弹出的线程。在这一时刻,我们处理的是线程,而不是中断。
第二种方法是将每个中断转换成在一个互斥量上的unlock操作,该互斥量对应正在等待的驱动程序。于是,中断的惟一效果就是导致某个线程变为就绪。
第三种方法是将一个中断转换成发送给某个线程的消息。低层代码只是构造一个表明中断来自何处的消息,将其排入队列,并且调用调度器以(潜在地)运行处理程序,而处理程序可能正在阻塞等待该消息。所有这些技术,以及其他类似的技术,都试图将中断转换成线程同步操作。让每个中断由一个适当的线程在适当的上下文中处理,比起在中断碰巧发生的随意上下文中运行处理程序,前者要更加容易管理。当然,这必须高效率地进行,而在操作系统内部深处,一切都必须高效率地进行。
大多数操作系统被设计成运行在多个硬件平台上。这些平台可以按照CPU芯片、MMU、字长、RAM大小以及不能容易地由HAL或等价物屏蔽的其他特性来区分。尽管如此,人们高度期望拥有单一的一组源文件用来生成所有的版本,否则,后来发现的每个程序错误必须在多个源文件中修改多次,从而有源文件逐渐疏远的危险。
某些硬件的差异,例如RAM大小,可以通过让操作系统在引导的时候确定其取值并且保存在一个变量中来处理。内存分配器可以利用RAM大小变量来确定构造多大的数据块高速缓存、页表等。甚至静态的表格,如进程表,也可以基于总的可用内存来确定大小。
然而,其他的差异,例如不同的CPU芯片,就不能让单一的二进制代码在运行的时候确定它正在哪一个CPU上运行。解决一个源代码多个目标机的问题的一种方法是使用条件编译。在源文件中,定义了一定的编译时标志用于不同的配置,并且这些标志用来将独立于CPU、字长、MMU等的代码用括号括起。例如,设想一个操作系统运行在Pentium和UltraSPARC芯片上,这就需要不同的初始化代码。可以像图13-6a中那样编写init过程的代码。根据CPU的取值(该值定义在头文件config.h中),实现一种初始化或其他的初始化过程。由于实际的二进制代码只包含目标机所需要的代码,这样就不会损失效率。
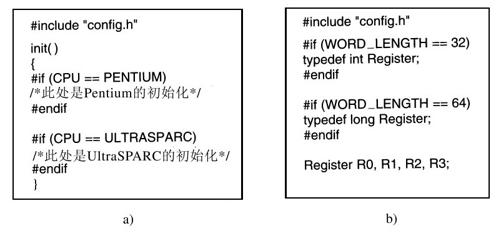
第二个例子,假设需要一个数据类型Register,它在Pentium上是32位,在UltraSPARC上是64位。这可以由图13-6b中的条件代码来处理(假设编译器产生32位的int和64位的long)。一旦做出这样的定义(可能是在别的什么地方的头文件中),程序员就可以只需声明变量为Register类型并且确信它们将具有正确的长度。
当然,头文件config.h必须正确地定义。对于Pentium处理器,它大概是这样的:
#define CPU PENTIUM
#define WORD_LENGTH 32
为了编译针对UltraSPARC的系统,应该使用不同的config.h,其中具有针对UltraSPARC的正确取值,它或许是这样的:
#define CPU ULTRASPARC
#define WORD_LENGTH 64
一些读者可能奇怪为什么CPU和WORD_LENGTH用不同的宏来处理。我们可以很容易地用针对CPU的测试而将Register的定义用括号括起,对于Pentium将其设置为32位,对于UltraSPARC将其设置为64位。然而,这并不是一个好主意。考虑一下以后当我们将系统移植到64位Intel Itanium处理器时会发生什么事情。我们可能不得不为了Itanium而在图13-6b中添加第三个条件。通过像上面那样定义宏,我们要做的全部事情是在config.h文件中为Itanium处理器包含如下的代码行:
#define WORD_LENGTH 64
这个例子例证了前面讨论过的正交性原则。那些依赖CPU的细节应该基于CPU宏而条件编译,而那些依赖字长的细节则应该使用WORD_LENGTH宏。类似的考虑对于许多其他参数也是适用的。
2.间接
人们不时地说在计算机科学中没有什么问题不能通过另一个层次间接得到解决。虽然有些夸大其词,但是其中的确存在一定程度的真实性。让我们考虑一些例子。在基于Pentium的系统上,当一个键被按下时,硬件将生成一个中断并且将键的编号而不是ASCII字符编码送到一个设备寄存器中。此外,当此键后来被释放时,第二个中断生成,同样伴随一个键编号。间接为操作系统使用键编号作为索引检索一张表格以获取ASCII字符提供了可能,这使得处理世界上不同国家使用的许多键盘十分容易。获得按下与释放两个信息使得将任何键作为换档键成为可能,因为操作系统知道键按下与释放的准确序列。
间接还被用在输出上。程序可以写ASCII字符到屏幕上,但是这些字符被解释为针对当前输出字体的一张表格的索引。表项包含字符的位图。这一间接使得将字符与字体相分离成为可能。
间接的另一个例子是UNIX中主设备号的使用。在内核内部,有一张表格以块设备的主设备号作为索引,还有另一张表格用于字符设备。当一个进程打开一个特定的文件(例如/dev/hd0)时,系统从i节点提取出类型(块设备或字符设备)和主副设备号,并且检索适当的驱动程序表以找到驱动程序。这一间接使得重新配置系统十分容易,因为程序涉及的是符号化的设备名,而不是实际的驱动程序名。
还有另一个间接的例子出现在消息传递的系统中,该系统命名一个邮箱而不是一个进程作为消息的目的地。通过间接使用邮箱(而不是指定一个进程作为目的地),能够获得相当可观的灵活性(例如,让一位秘书处理她的老板的消息)。
在某种意义上,使用诸如
#define PROC_TABLE_SIZE 256
的宏也是间接的一种形式,因为程序员无须知道表格实际有多大就可以编写代码。一个良好的习惯是为所有的常量提供符号化的名字(有时-1、0和1除外),并且将它们放在头文件中,同时提供注释解释它们代表什么。
3.可重用性
在略微不同的上下文中重用相同的代码通常是可行的。这样做是一个很好的想法,因为它减少了二进制代码的大小并且意味着代码只需要调试一次。例如,假设用位图来跟踪磁盘上的空闲块。磁盘块管理可以通过提供管理位图的过程alloc和free得到处理。
在最低限度上,这些过程应该对任何磁盘起作用。但是我们可以比这更进一步。相同的过程还可以用于管理内存块、文件系统块高速缓存中的块,以及i节点。事实上,它们可以用来分配与回收能够线性编号的任意资源。
4.重入
重入指的是代码同时被执行两次或多次的能力。在多处理器系统上,总是存在着这样的危险:当一个CPU执行某个过程时,另一个CPU在第一个完成之前也开始执行它。在这种情况下,不同CPU上的两个(或多个)线程可能在同时执行相同的代码。这种情况必须通过使用互斥量或者某些其他保护临界区的方法进行处理。
然而,在单处理器上,问题也是存在的。特别地,大多数操作系统是在允许中断的情况下运行的。否则,将丢失许多中断并且使系统不可靠。当操作系统忙于执行某个过程P时,完全有可能发生一个中断并且中断处理程序也调用P。如果P的数据结构在中断发生的时刻处于不一致的状态,中断处理程序就会注意到它们处于不一致的状态并且失败。
可能发生这种情况的一个显而易见的例子是P是调度器。假设某个进程用完了它的时间配额,并且操作系统正将其移动到其队列的末尾。在列表处理的半路,中断发生了,使得某个进程就绪,并且运行调度器。由于队列处于不一致的状态,系统有可能会崩溃。因此,即使在单处理器上,最好是操作系统的大部分为可重入的,关键的数据结构用互斥量来保护,并且在中断不被允许的时刻禁用中断。
5.蛮力法
使用蛮力法解决问题多年以来获得了较差的名声,但是依据简单性它经常是行之有效的方法。每个操作系统都有许多很少会调用的过程或是具有很少数据的操作,不值得对它们进行优化。例如,在系统内部经常有必要搜索各种表格和数组。蛮力算法只是让表格保持表项建立时的顺序,并且当必须查找某个东西时线性地搜索表格。如果表项的数目很少(例如少于1000个),对表格排序或建立散列表的好处不大,但是代码却复杂得多并且很有可能在其中存在错误。
当然,对处于关键路径上的功能,例如上下文切换,使它们加快速度的一切措施都应该尽力去做,即使可能要用汇编语言编写它们。但是,系统的大部分并不处于关键路径上。例如,许多系统调用很少被调用。如果每隔1秒有一个fork调用,并且该调用花费1毫秒完成,那么即便将其优化到花费0秒也不过仅有0.1%的获益。如果优化过的代码更加庞大且有更多错误,那就不必多此一举了。
6.首先检查错误
由于各种各样的原因,许多系统调用可能潜在地会失败:要打开的文件属于他人;因为进程表满而创建进程失败;或者因为目标进程不存在而使信号不能被发送。操作系统在执行调用之前必须无微不至地检查每一个可能的错误。
许多系统调用还需要获得资源,例如进程表的空位、i节点表的空位或文件描述符。一般性的建议是在获得资源之前,首先进行检查以了解系统调用能否实际执行,这样可以省去许多麻烦。这意味着,将所有的测试放在执行系统调用的过程的开始。每个测试应该具有如下的形式:
if(error_condition)return(ERROR_CODE);
如果调用通过了所有严格的测试,那么就可以肯定它将会取得成功。在这一时刻它才能获得资源。
如果将获得资源的测试分散开,那么就意味着如果在这一过程中某个测试失败,到这一时刻已经获得的所有资源都必须归还。如果在这里发生了一个错误并且资源没有被归还,可能并不会立刻发生破坏。例如,一个进程表项可能只是变得永久地不可用。然而,随着时间的流逝,这一差错可能会触发多次。最终,大多数或全部进程表项可能都会变得不可用,导致系统以一种极度不可预料且难以调试的方式崩溃。
许多系统以内存泄漏的形式遭受了这一问题的侵害。典型地,程序调用malloc分配了空间,但是以后忘记了调用free释放它。逐渐地,所有的内存都消失了,直到系统重新启动。
Engler等人(2000)推荐了一种有趣的方法在编译时检查某些这样的错误。他们注意到程序员知道许多定式而编译器并不知道,例如当你锁定一个互斥量的时候,所有在锁定操作处开始的路径都必须包含一个解除锁定的操作并且在相同的互斥量上没有更多的锁定。他们设计了一种方法让程序员将这一事实告诉编译器,并且指示编译器在编译时检查所有路径以发现对定式的违犯。程序员还可以设定已分配的内存必须在所有路径上释放,以及设定许多其他的条件。










