预计阅读本页时间:-

3.3.3 加速分页过程
我们已经了解了虚拟内存和分页的基础。现在是时候深入到更多关于可能的实现的细节中去了。在任何分页式系统中,都需要考虑两个主要问题:
1)虚拟地址到物理地址的映射必须非常快。
2)如果虚拟地址空间很大,页表也会很大。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
第一个问题是由于每次访问内存,都需要进行虚拟地址到物理地址的映射。所有的指令最终都必须来自内存,并且很多指令也会访问内存中的操作数。因此,每条指令进行一两次或更多页表访问是必要的。如果执行一条指令需要1ns,页表查询必须在0.2ns之内完成,以避免映射成为一个主要瓶颈。
第二个问题来自现代计算机使用至少32位的虚拟地址,而且64位变得越来越普遍。假设页长为4KB,32位的地址空间将有100万页,而64位地址空间简直多到超乎你的想象。如果虚拟地址空间中有100万个页,那么页表必然有100万条表项。另外请记住,每个进程都需要自己的页表(因为它有自己的虚拟地址空间)。
对大而快速的页映射的需求成为了构建计算机的重要约束。最简单的设计(至少从概念上)是使用由一组“快速硬件寄存器”组成的单一页表,每一个表项对应一个虚页,虚页号作为索引,如图3-10所示。当启动一个进程时,操作系统把保存在内存中的进程页表的副本载入到寄存器中。在进程运行过程中,不必再为页表而访问内存。这个方法的优势是简单并且在映射过程中不需要访问内存。而缺点是在页表很大时,代价高昂。而且每一次上下文切换都必须装载整个页表,这样会降低性能。
另一种极端方法是,整个页表都在内存中。那时所需的硬件仅仅是一个指向页表起始位置的寄存器。这样的设计使得在上下文切换时,进行“虚拟地址到物理地址”的映射只需重新装入一个寄存器。当然,这种做法的缺陷是在执行每条指令时,都需要一次或多次内存访问,以完成页表项的读入,速度非常慢。
1.转换检测缓冲区
现在讨论加速分页机制和处理大的虚拟地址空间的实现方案,先介绍加速分页问题。大多数优化技术都是从内存中的页表开始的。这种设计对效率有着巨大的影响。例如,假设一条指令要把一个寄存器中的数据复制到另一个寄存器。在不分页的情况下,这条指令只访问一次内存,即从内存中取指令。有了分页后,则因为要访问页表而引起更多次的访问内存。由于执行速度通常被CPU从内存中取指令和数据的速度所限制,所以每次内存访问必须进行两次页表访问会降低一半的性能。在这种情况下,没人会采用分页机制。
多年以来,计算机的设计者已经意识到了这个问题,并找到了一种解决方案。这种解决方案的建立基于这样一种现象:大多数程序总是对少量的页面进行多次的访问,而不是相反的。因此,只有很少的页表项会被反复读取,而其他的页表项很少被访问。
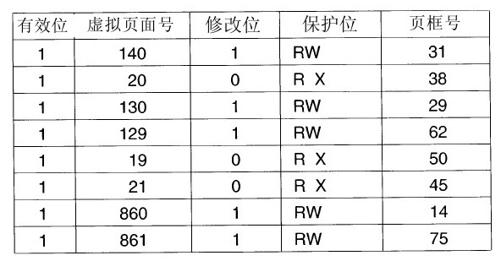
上面提到的解决方案是为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再访问页表。这种设备称为转换检测缓冲区(Translation Lookaside Buffer,TLB),有时又称为相联存储器(associate memory),如图3-12所示。它通常在MMU中,包含少量的表项,在此例中为8个,在实际中很少会超过64个。每个表项记录了一个页面的相关信息,包括虚拟页号、页面的修改位、保护码(读/写/执行权限)和该页所对应的物理页框。除了虚拟页号(不是必须放在页表中的),这些域与页表中的域是一一对应的。另外还有一位用来记录这个表项是否有效(即是否在使用)。
如果一个进程在虚拟地址19、20和21之间有一个循环,那么可能会生成图3-12中的TLB。因此,这三个表项中有可读和可执行的保护码。当前主要使用的数据(假设是个数组)放在页面129和页面130中。页面140包含了用于数组计算的索引。最后,堆栈位于页面860和页面861。
现在看一下TLB是如何工作的。将一个虚拟地址放入MMU中进行转换时,硬件首先通过将该虚拟页号与TLB中所有表项同时(即并行)进行匹配,判断虚拟页面是否在其中。如果发现了一个有效的匹配并且要进行的访问操作并不违反保护位,则将页框号直接从TLB中取出而不必再访问页表。如果虚拟页面号确实是在TLB中,但指令试图在一个只读页面上进行写操作,则会产生一个保护错误,就像对页表进行非法访问一样。
当虚拟页号不在TLB中时发生的事情值得讨论。如果MMU检测到没有有效的匹配项时,就会进行正常的页表查询。接着从TLB中淘汰一个表项,然后用新找到的页表项代替它。这样,如果这一页面很快再被访问,第二次访问TLB时自然将会命中而不是不命中。当一个表项被清除出TLB时,将修改位复制到内存中的页表项,而除了访问位,其他的值不变。当页表项中从页表装入到TLB中时,所有的值都来自内存。
2.软件TLB管理
到目前为止,我们已经假设每一台具有虚拟内存的机器都具有由硬件识别的页表,以及一个TLB。在这种设计中,对TLB的管理和TLB的失效处理都完全由MMU硬件来实现。只有在内存中没有找到某个页面时,才会陷入到操作系统中。
在过去,这样的假设是正确的。但是,许多现代的RISC机器,包括SPARC、MIPS以及HP PA,几乎所有的页面管理都是在软件中实现的。在这些机器上,TLB表项被操作系统显式地装载。当发生TLB访问失效,不再是由MMU到页表中查找并取出需要的页表项,而是生成一个TLB失效并将问题交给操作系统解决。系统必须先找到该页面,然后从TLB中删除一个项,接着装载一个新的项,最后再执行先前出错的指令。当然,所有这一切都必须在有限的几条指令中完成,因为TLB失效比缺页中断发生的更加频繁。
让人感到惊奇的是,如果TLB大(如64个表项)到可以减少失效率时,TLB的软件管理就会变得足够有效。这种方法的最主要的好处是获得了一个非常简单的MMU,这就在CPU芯片上为高速缓存以及其他改善性能的设计腾出了相当大的空间。Uhlig等人在论文(Uhlig,1994)中讨论过软件TLB管理。
到目前为止,已经开发了多种不同的策略来改善使用软件TLB管理的机器的性能。其中一种策略是在减少TLB失效的同时,又要在发生TLB失效时减少处理开销(Bala等人,1994)。为了减少TLB失效,有时候操作系统能用“直觉”指出哪些页面下一步可能会被用到并预先为它们在TLB中装载表项。例如,当一个客户进程发送一条消息给同一台机器上的服务器进程,很可能服务器将不得不立即运行。了解了这一点,当执行处理send的陷阱时,系统也可以找到服务器的代码页、数据页以及堆栈页,并在有可能导致TLB失效前把它们装载到TLB中。
无论是用硬件还是用软件来处理TLB失效,常见方法都是找到页表并执行索引操作以定位将要访问的页面。用软件做这样的搜索的问题是,页表可能不在TLB中,这就会导致处理过程中的额外的TLB失效。可以通过在内存中的固定位置维护一个大的(如4KB)TLB表项的软件高速缓存(该高速缓存的页面总是被保存在TLB中)来减少TLB失效。通过首先检查软件高速缓存,操作系统能够实质性地减少TLB失效。
当使用软件TLB管理时,一个基本要求是要理解两种不同的TLB失效的区别在哪里。当一个页面访问在内存中而不在TLB中时,将产生软失效(soft miss)。那么此时所要做的就是更新一下TLB,不需要产生磁盘I/O。典型的处理需要10~20个机器指令并花费几个纳秒完成操作。相反,当页面本身不在内存中(当然也不在TLB中)时,将产生硬失效。此刻需要一次磁盘存取以装入该页面,这个过程大概需要几毫秒。硬失效的处理时间往往是软失效的百万倍。










