预计阅读本页时间:-

第10章
模拟登录
目前,大部分网站都具有用户登录功能,其中某些网站只有在用户登录后才能获得有价值的信息,在爬取这类网站时,Scrapy爬虫程序需要先模拟用户登录,再爬取内容,这一章来学习在Scrapy中模拟登录的方法。
10.1 登录实质
在学习模拟登录前,应先对网站登录的原理有所了解,我们在Chrome浏览器中跟踪一次实际的登录操作,观察浏览器与网站服务器是如何交互的。以登录http://example.webscraping.com网站为例进行演示,这是一个专门用于练习爬虫技术的网站,图10-1所示为该网站的登录页面。
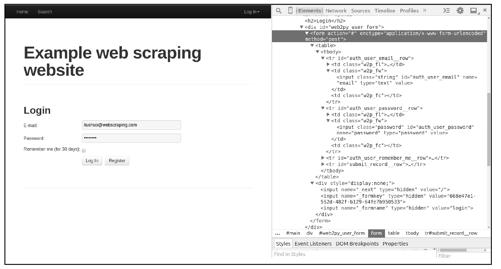
页面中的表单对应于HTML中的<form>元素,当填写完表单,单击“提交”按钮时,浏览器会根据<form>元素的内容发送一个HTTP请求给服务器,其中:
● <form>的method属性决定了HTTP请求的方法(本例中为POST)。
● <form>的action属性决定了HTTP请求的url(本例中为#,也就是当前页面的url)。
● <form>的enctype属性决定了表单数据的编码类型(本例中为x-www-urlencoded)。
● <form>中的<input>元素决定了表单数据的内容。
再来看<form>中的<input>元素:
● name属性为'email'和'password'的两个<input>,对应于账号和密码输入框,它们的值待用户填写。
● 在<div style="display:none;">中还包含了3个隐藏的<input type="hidden">,它们的值在value属性中,虽然值不需要用户填写,但提交的表单数据中缺少它们可能会导致登录验证失败,这些隐藏的<input>有其他一些用途,比如:
 <input name="_next">用来告诉服务器,登录成功后页面跳转的地址。
<input name="_next">用来告诉服务器,登录成功后页面跳转的地址。
<input name="_formkey">用来防止CSRF跨域攻击,相关内容请查阅资料。
接下来,填入账号密码,在Chrome开发者工具中观察单击Log In按钮后浏览器发送的HTTP请求,如图10-2所示。
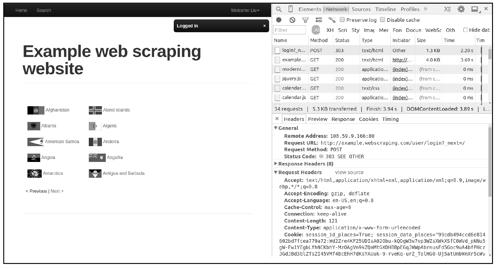
图10-2
从图10-2中可以看出,我们捕获到了很多HTTP请求,其中第一个就是发送登录表单的POST请求,查看该HTTP请求,可以找到请求url、请求方法(method)、请求头部(headers)、表单数据(form data)等信息,其中我们最关心的是表单数据,如图10-3所示。
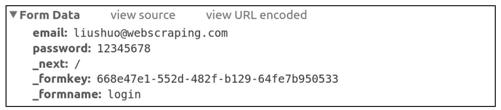
图10-3
表单数据由多个键值对构成,每个键值对对应一个<input>元素,其中的键是<input>的name属性,值是<input>的value属性(用户填写的内容会成为<input>的value)。需要注意的是,图10-3中显示的并不是实际的POST正文(content),这样的显示方式只是为了方便用户查看。单击view source按钮,可以看到实际的POST正文,如图10-4所示。

图10-4
分析过HTTP请求信息后,再来看HTTP响应信息,如图10-5所示。
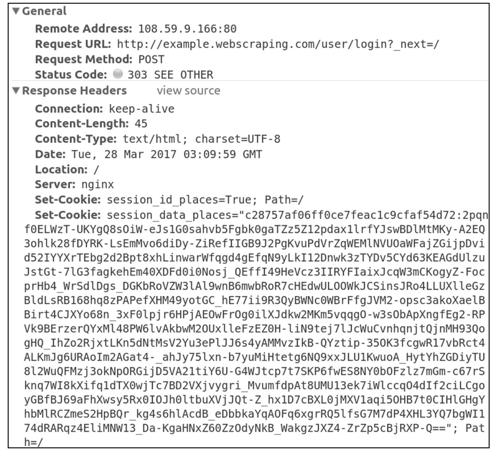
图10-5
响应头部中长长的Set-Cookie字段就是网站服务器程序保存在客户端(浏览器)的Cookie信息,其中包含标识用户身份的session信息,之后对该网站发送的其他HTTP请求都会带上这个“身份证”(session信息),服务器程序通过这个“身份证”识别出发送请求的用户,从而决定响应怎样的页面。另外,响应的状态码是303,它代表页面重定向,浏览器会读取响应头部中的Location字段,依据其中描述的路径(本例中为/)再次发送一个GET请求,图10-6所示为这个GET请求的信息。
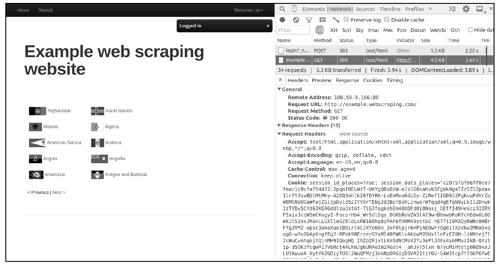
图10-6
观察请求头部中的Cookie字段,它携带了之前POST请求获取的Cookie信息,最终浏览器用该请求响应的HTML文档刷新了页面,在页面右上角可以看到Welcome Liu的字样,表明这是登录成功后的页面。
10.2 Scrapy模拟登录
10.2.1 使用FormRequest
现在大家了解了登录的实质,其核心是向服务器发送含有登录表单数据的HTTP请求(通常是POST)。Scrapy提供了一个FormRequest类(Request的子类),专门用于构造含有表单数据的请求,FormRequest的构造器方法有一个formdata参数,接收字典形式的表单数据。接下来,我们在scrapy shell环境下演示如何使用FormRequest模拟登录。
首先爬取登录页面http://example.webscraping.com/user/login:
$ scrapy shell http://example.webscraping.com/user/login
通过之前的分析,我们已经了解了表单数据应包含的信息:账号和密码信息,再加3个隐藏<input>中的信息。先把这些信息收集到一个字典中,然后使用这个表单数据字典构造FormRequest对象:
>>> # 先提取3 个隐藏<input>中包含的信息,它们在<div style="display:none;">中
>>> sel = response.xpath('//div[@style]/input')
>>> sel
[<Selector xpath='//div[@style]/input' data='<input name="_next" type="hidden" value='>,
<Selector xpath='//div[@style]/input' data='<input name="_formkey" type="hidden" val'>,
<Selector xpath='//div[@style]/input' data='<input name="_formname" type="hidden" va'>]
>>> # 构造表单数据字典
>>> fd = dict(zip(sel.xpath('./@name').extract(), sel.xpath('./@value').extract()))
>>> fd
{'_formkey': '432dcb0c-0d85-443f-bb50-9644cfeb2f2b',
'_formname': 'login',
'_next': '/'}
>>> # 填写账号和密码信息
>>> fd['email'] = 'liushuo@webscraping.com'
>>> fd['password'] = '12345678'
>>> fd
{'_formkey': '432dcb0c-0d85-443f-bb50-9644cfeb2f2b',
'_formname': 'login',
'_next': '/',
'email': 'liushuo@webscraping.com',
'password': '12345678'}
>>> from scrapy.http import FormRequest
>>> request = FormRequest('http://example.webscraping.com/user/login', formdata=fd)
以上是直接构造FormRequest对象的方式,除此之外还有一种更为简单的方式,即调用FormRequest的from_response方法。调用时需传入一个Response对象作为第一个参数,该方法会解析Response对象所包含页面中的<form>元素,帮助用户创建FormRequest对象,并将隐藏<input>中的信息自动填入表单数据。使用这种方式,我们只需通过formdata参数填写账号和密码即可,代码如下:
>>> fd = {'email': 'liushuo@webscraping.com', 'password': '12345678'}
>>> request = FormRequest.from_response(response, formdata=fd)
使用任意方式构造好FormRequest对象后,接下来提交表单请求:
>>> fetch(request)
[scrapy] DEBUG: Redirecting (303) to <GET http://example.webscraping.com/> from
<POST http://example.webscraping.com/user/login>
[scrapy] DEBUG: Crawled (200) <GET http://example.webscraping.com/> (referer: None)
在log信息中,可以看到和浏览器提交表单时类似的情形:POST请求的响应状态码为303,之后Scrapy自动再发送一个GET请求下载跳转页面。此时,可以通过在页面中查找特殊字符串或在浏览器中查看页面验证登录是否成功,如图10-7所示。
>>> 'Welcome Liu' in response.text
True
>>> view(response)
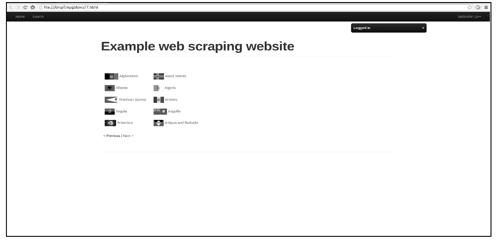
图10-7
验证结果表明模拟登录成功了。显然,Scrapy发送的第2个GET请求携带了第1个POST请求获取的Cookie信息,为请求附加Cookie信息的工作是由Scrapy内置的下载中间件CookiesMiddleware自动完成的。现在,我们可以继续发送请求,爬取那些只有登录后才能获取的信息了,这里以爬取用户个人信息为例,如图10-8所示。
>>> fetch('http://example.webscraping.com/user/profile') #下载用户个人信息页面
[scrapy] DEBUG: Crawled (200) <GET http://example.webscraping.com/user/profile>
>>> view(response)
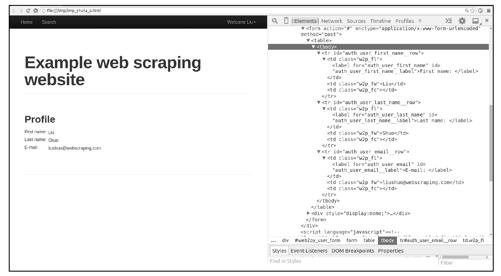
图10-8
提取页面中的用户个人信息,代码如下:
>>> keys = response.css('table label::text').re('(.+):')
>>> keys
['First name', 'Last name', 'E-mail']
>>> values = response.css('table td.w2p_fw::text').extract()
>>> values
['Liu', 'Shuo', 'liushuo@webscraping.com']
>>> dict(zip(keys, values))
{'E-mail': 'liushuo@webscraping.com', 'First name': 'Liu', 'Last name': 'Shuo'}
到此,使用FormRequest模拟登录的过程就演示完了。
10.2.2 实现登录Spider
整理10.2.1小节中登录http://example.webscraping.com后爬取用户个人信息的代码,实现一个LoginSpider,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
class LoginSpider(scrapy.Spider):
name = "login"
allowed_domains = ["example.webscraping.com"]
start_urls = ['http://example.webscraping.com/user/profile']
def parse(self, response):
# 解析登录后下载的页面,此例中为用户个人信息页面
keys = response.css('table label::text').re('(.+):')
values = response.css('table td.w2p_fw::text').extract()
yield dict(zip(keys, values))
# ----------------------------登录---------------------------------
# 登录页面的url
login_url = 'http://example.webscraping.com/user/login'
def start_requests(self):
yield Request(self.login_url, callback=self.login)
def login(self, response):
# 登录页面的解析函数,构造FormRequest对象提交表单
fd = {'email': 'liushuo@webscraping.com', 'password': '12345678'}
yield FormRequest.from_response(response, formdata=fd,
callback=self.parse_login)
def parse_login(self, response):
# 登录成功后,继续爬取start_urls 中的页面
if 'Welcome Liu' in response.text:
yield from super().start_requests() # Python 3语法
解释上述代码如下:
● 覆写基类的start_requests方法,最先请求登录页面。
● login方法为登录页面的解析函数,在该方法中进行模拟登录,构造表单请求并提交。
● parse_login方法为表单请求的响应处理函数,在该方法中通过在页面查找特殊字符串'Welcome Liu'判断是否登录成功,如果成功,调用基类的start_requests方法,继续爬取start_urls中的页面。
我们这样设计LoginSpider就是想把模拟登录和爬取内容的代码分离开,使得逻辑上更加清晰。
10.3 识别验证码
目前,很多网站为了防止爬虫爬取,登录时需要用户输入验证码。下面我们学习如何在爬虫程序中识别验证码(在举例过程中不指明具体网站)。
图10-9所示为某网站登录页面,其中包含验证码。
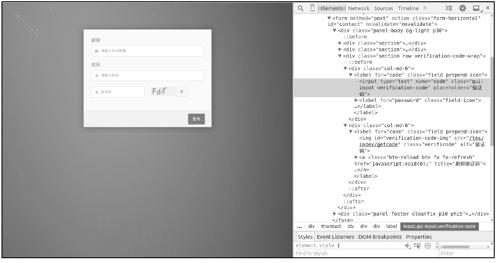
图10-9
页面中的验证码图片对应一个<img>元素,即一张图片,浏览器加载完登录页面后,会携带之前访问获取的Cookie信息,继续发送一个HTTP请求加载验证码图片。和账号密码输入框一样,验证码输入框也对应一个<input>元素,因此用户输入的验证码会成为表单数据的一部分,表单提交后由网站服务器程序验证。
识别验证码有多种方式,下面介绍常用的几种。
10.3.1 OCR识别
OCR是光学字符识别的缩写,用于在图像中提取文本信息,tesseract-ocr是利用该技术实现的一个验证码识别库,在Python中可以通过第三方库pytesseract调用它。下面介绍如何使用pytesseract识别验证码。
首先安装tesseract-ocr,在Ubuntu下可以使用apt-get安装:
sudo apt-get install tesseract-ocr
接下来安装pytesseract,它依赖于Python图像处理库PIL或Pillow(PIL和Pillow功能类似,任选其一),可以使用pip安装它们:
$ pip install pillow
$ pip install pytesseract
现在,我们使用pytesseract识别图片code.png中的验证码,代码如下:

>>> from PIL import Image
>>> import pytesseract
>>> img = Image.open('code.png')
>>> img = img.convert('L')
>>> pytesseract.image_to_string(img)
'cqKE'
上面的代码中,先使用Image.open打开图片,为了提高识别率,调用Image对象的convert方法把图片转换为黑白图,然后将黑白图传递给pytesseract.image_to_string方法进行识别,这里我们幸运地识别成功了。经测试,此段代码对于X网站中的验证码识别率可以达到72%,这已经足够高了。
下面我们以之前的LoginSpider为模板实现一个使用pytesseract识别验证码登录的Spider:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request, FormRequest
import json
from PIL import Image
from io import BytesIO
import pytesseract
from scrapy.log import logger
class CaptchaLoginSpider(scrapy.Spider):
name = "login_captcha"
start_urls = ['http://XXX.com/']
def parse(self, response):
...
# X 网站登录页面的url(虚构的)
login_url = 'http://XXX.com/login'
user = 'liushuo@XXX.com'
password = '12345678'
def start_requests(self):
yield Request(self.login_url, callback=self.login, dont_filter=True)
def login(self, response):
# 该方法既是登录页面的解析函数,又是下载验证码图片的响应处理函数
# 如果response.meta['login_response']存在,当前response 为验证码图片的响应
# 否则当前response 为登录页面的响应
login_response = response.meta.get('login_response')
if not login_response:
# Step 1:
# 此时response 为登录页面的响应,从中提取验证码图片的url,下载验证码图片
captchaUrl = response.css('label.field.prepend-icon img::attr(src)')\
.extract_first()
captchaUrl = response.urljoin(captchaUrl)
# 构造Request 时,将当前response 保存到meta 字典中
yield Request(captchaUrl,
callback=self.login,
meta={'login_response': response},
dont_filter=True)
else:
# Step 2:
# 此时,response 为验证码图片的响应,response.body是图片二进制数据
# login_response 为登录页面的响应,用其构造表单请求并发送
formdata = {
'email': self.user,
'pass': self.password,
# 使用OCR识别
'code': self.get_captcha_by_OCR(response.body),
}
yield FormRequest.from_response(login_response,
callback=self.parse_login,
formdata=formdata, dont_filter=True)
def parse_login(self, response):
# 根据响应结果判断是否登录成功
info = json.loads(response.text)
if info['error'] == '0':
logger.info('登录成功:-)')
return super().start_requests()
logger.info('登录失败:-(, 重新登录...')
return self.start_requests()
def get_captcha_by_OCR(self, data):
# OCR识别
img = Image.open(BytesIO(data))
img = img.convert('L')
captcha = pytesseract.image_to_string(img)
img.close()
return captcha
解释上述代码如下:
● login方法
带有验证码的登录,需要额外发送一个HTTP请求来获取验证码图片,这里的login方法既处理下载登录页面的响应,又处理下载验证码图片的响应。
解析登录页面时,提取验证码图片的url,发送请求下载图片,并将登录页面的Response对象保存到Request对象的meta字典中。
处理下载验证码图片的响应时,调用get_captcha_by_OCR方法识别图片中的验证码,然后将之前保存的登录页面的Response对象取出,构造FormRequest对象并提交。
● get_captcha_by_OCR方法
参数data是验证码图片的二进制数据,类型为bytes,想要使用Image.open函数构造Image对象,先要把图片的二进制数据转换成某种类文件对象,这里使用BytesIO进行包裹,获得Image对象后先将其转换成黑白图,然后调用pytesseract.image_to_string方法进行识别。
● parse_login方法
处理表单请求的响应。响应正文是一个json串,其中包含了用户验证的结果,先调用json.loads将正文转换为Python字典,然后依据其中error字段的值判断登录是否成功,若登录成功,则从start_urls中的页面开始爬取;若登录失败,则重新登录。
10.3.2 网络平台识别
在10.3.1小节中,使用pytesseract识别的验证码比较简单,对于某些复杂的验证码,pytesseract的识别率很低或者无法识别。目前,有很多网站专门提供验证码识别服务,可以识别较为复杂的验证码(有些是人工处理的),它们被称之为验证码识别平台,这些平台多数是付费使用的,价格大约为1元钱识别100个验证码,平台提供了HTTP服务接口,用户可以通过HTTP请求将验证码图片发送给平台,平台识别后将结果通过HTTP响应返回。
在阿里云市场可以找到很多验证码识别平台,我们随意挑选了一个,如图10-10和图10-11所示。
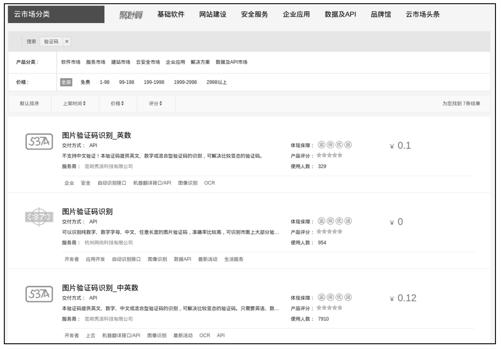
图10-10
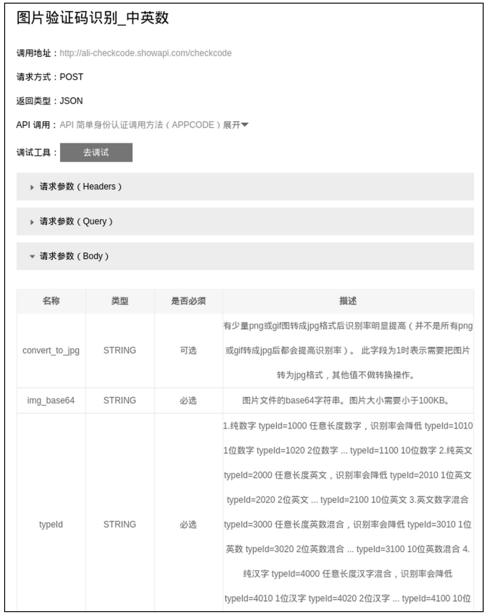
图10-11
购买服务后,我们利用该平台识别图片code.gif中较为复杂的验证码:

阅读API文档,实现代码如下:
import requests
import base64
from pprint import pprint
# 购买服务后,平台发放给我们一个appcode,用来识别请求者的身份
APPCODE = 'f239ccawf37f287418a90e2f922649273c4'
url = 'http://ali-checkcode.showapi.com/checkcode'
img_data = open('code.gif', 'rb').read()
form = {}
# 不转换为jpg
form['convert_to_jpg'] = '0'
# 对图片进行base64 编码
form['img_base64'] = base64.b64encode(img_data)
# 7 位汉字
form['typeId'] = '4070'
# 用户验证
headers = {'Authorization': 'APPCODE ' + APPCODE}
response = requests.post(url, headers=headers, data=form)
pprint(response.json())
表单中3个字段含义如下:
● convert_to_jpg是否将图片转换为jpg格式。
● img_base64图片数据的base64编码。
● typeId验证码类型,这里的'4070'代表7位汉字。
运行脚本,并观察结果:
$ python3 ali_checkcode.py
{'showapi_res_body': {'Id': '4d5fea-21eb-4043-8236-d478031916',
'Result': '损俱饶现渊弹翠',
'ret_code': 0},
'showapi_res_code': 0,
'showapi_res_error': ''}
如上所示,识别成功了。
现在,我们把使用平台识别验证码的方式也加入CaptchaLoginSpider中,只需添加一个get_captcha_by_network方法:
class CaptchaLoginSpider(scrapy.Spider):
...
def get_captcha_by_OCR(self, data):
# OCR识别
img = Image.open(BytesIO(data))
img = img.convert('L')
captcha = pytesseract.image_to_string(img)
img.close()
return captcha
def get_captcha_by_network(self, data):
# 平台识别
import requests
url = 'http://ali-checkcode.showapi.com/checkcode'
appcode = 'f23cca37f287418a90e2f922649273c4'
form = {}
form['convert_to_jpg'] = '0'
form['img_base64'] = base64.b64encode(data)
form['typeId'] = '3040'
headers = {'Authorization': 'APPCODE ' + appcode}
response = requests.post(url, headers=headers, data=form)
res = response.json()
if res['showapi_res_code'] == 0:
return res['showapi_res_body']['Result']
return ''
10.3.3 人工识别
最后讲解的方法听起来似乎很笨:人工识别。通常网站只需登录一次便可爬取,在其他识别方式不管用时,人工识别一次验证码也是可行的,其实现也非常简单——在Scrapy下载完验证码图片后,调用Image.show方法将图片显示出来,然后调用Python内置的input函数,等待用户肉眼识别后输入识别结果。
我们将人工识别的方式也加入CaptchaLoginSpider中,再添加一个get_captcha_by_user方法:
class CaptchaLoginSpider(scrapy.Spider):
...
def get_captcha_by_OCR(self, data):
# OCR识别
img = Image.open(BytesIO(data))
img = img.convert('L')
captcha = pytesseract.image_to_string(img)
img.close()
return captcha
def get_captcha_by_network(self, data):
# 平台识别
import requests
url = 'http://ali-checkcode.showapi.com/checkcode'
appcode = 'f23cca37f287418a90e2f922649273c4'
form = {}
form['convert_to_jpg'] = '0'
form['img_base64'] = base64.b64encode(data)
form['typeId'] = '3040'
headers = {'Authorization': 'APPCODE ' + appcode}
response = requests.post(url, headers=headers, data=form)
res = response.json()
if res['showapi_res_code'] == 0:
return res['showapi_res_body']['Result']
return ''
def get_captcha_by_user(self, data):
# 人工识别
img = Image.open(BytesIO(data))
img.show()
captcha = input('输入验证码:')
img.close()
return captcha
10.4 Cookie登录
在10.3节,我们讲解了识别验证码登录的方法,但目前网站的验证码越来越复杂,某些验证码已经复杂到人类难以识别的程度,有些时候提交表单登录的路子难以走通。此时,我们可以换一种登录爬取的思路,在使用浏览器登录网站后,包含用户身份信息的Cookie会被浏览器保存在本地,如果Scrapy爬虫能直接使用浏览器中的Cookie发送HTTP请求,就可以绕过提交表单登录的步骤。
10.4.1 获取浏览器Cookie
我们无须费心钻研,各种浏览器将Cookie以哪种形式存储在哪里,使用第三方Python库browsercookie便可以获取Chrome和Firefox浏览器中的Cookie。
使用pip安装browsercookie:
pip install browsercookie
browsercookie的使用非常简单,示例代码如下:
>>> import browsercookie
>>> chrome_cookiejar = browsercookie.chrome() # 获取Chrome 浏览器中的Cookie
>>> firefox_cookiejar = browsercookie.firefox() # 获取Firefox 浏览器中的Cookie
>>> type(chrome_cookiejar)
http.cookiejar.CookieJar
>>> for cookie in chrome_cookiejar:
... print(cookie)
browsercookie的chrome和firefox方法分别返回Chrome和Firefox浏览器中的Cookie,返回值是一个http.cookiejar.CookieJar对象,对CookieJar对象进行迭代,可以访问其中的每个Cookie对象。
10.4.2 CookiesMiddleware源码分析
之前曾提到过,Scrapy爬虫所使用的Cookie由内置下载中间件CookiesMiddleware自动处理。下面我们来分析一下CookiesMiddleware是如何工作的,其源码如下:
import os
import six
import logging
from collections import defaultdict
from scrapy.exceptions import NotConfigured
from scrapy.http import Response
from scrapy.http.cookies import CookieJar
from scrapy.utils.python import to_native_str
logger = logging.getLogger(__name__)
class CookiesMiddleware(object):
"""This middleware enables working with sites that need cookies"""
def __init__(self, debug=False):
self.jars = defaultdict(CookieJar)
self.debug = debug
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.getbool('COOKIES_ENABLED'):
raise NotConfigured
return cls(crawler.settings.getbool('COOKIES_DEBUG'))
def process_request(self, request, spider):
if request.meta.get('dont_merge_cookies', False):
return
cookiejarkey = request.meta.get("cookiejar")
jar = self.jars[cookiejarkey]
cookies = self._get_request_cookies(jar, request)
for cookie in cookies:
jar.set_cookie_if_ok(cookie, request)
# set Cookie header
request.headers.pop('Cookie', None)
jar.add_cookie_header(request)
self._debug_cookie(request, spider)
def process_response(self, request, response, spider):
if request.meta.get('dont_merge_cookies', False):
return response
# extract cookies from Set-Cookie and drop invalid/expired cookies
cookiejarkey = request.meta.get("cookiejar")
jar = self.jars[cookiejarkey]
jar.extract_cookies(response, request)
self._debug_set_cookie(response, spider)
return response
def _debug_cookie(self, request, spider):
if self.debug:
cl = [to_native_str(c, errors='replace')
for c in request.headers.getlist('Cookie')]
if cl:
cookies = "\n".join("Cookie: {}\n".format(c) for c in cl)
msg = "Sending cookies to: {}\n{}".format(request, cookies)
logger.debug(msg, extra={'spider': spider})
def _debug_set_cookie(self, response, spider):
if self.debug:
cl = [to_native_str(c, errors='replace')
for c in response.headers.getlist('Set-Cookie')]
if cl:
cookies = "\n".join("Set-Cookie: {}\n".format(c) for c in cl)
msg = "Received cookies from: {}\n{}".format(response, cookies)
logger.debug(msg, extra={'spider': spider})
def _format_cookie(self, cookie):
# build cookie string
cookie_str = '%s=%s' % (cookie['name'], cookie['value'])
if cookie.get('path', None):
cookie_str += '; Path=%s' % cookie['path']
if cookie.get('domain', None):
cookie_str += '; Domain=%s' % cookie['domain']
return cookie_str
def _get_request_cookies(self, jar, request):
if isinstance(request.cookies, dict):
cookie_list = [{'name': k, 'value': v} for k, v in \
six.iteritems(request.cookies)]
else:
cookie_list = request.cookies
cookies = [self._format_cookie(x) for x in cookie_list]
headers = {'Set-Cookie': cookies}
response = Response(request.url, headers=headers)
return jar.make_cookies(response, request)
分析其中几个核心方法如下:
● from_crawler方法
从配置文件中读取COOKIES_ENABLED,决定是否启用该中间件。如果启用,调用构造器创建对象,否则抛出NotConfigured异常,Scrapy将忽略该中间件。
● __init__方法
使用标准库中的collections.defaultdict创建一个默认字典self.jars,该字典中每一项的值都是一个scrapy.http.cookies.CookieJar对象,CookiesMiddleware可以让Scrapy爬虫同时使用多个不同的CookieJar。例如,在某网站我们注册了两个账号account1和account2,假设一个爬虫想同时登录两个账号对网站进行爬取,为了避免Cookie冲突(通俗地讲,登录一个会替换掉另一个),此时可以让每个账号发送的HTTP请求使用不同的CookieJar,在构造Request对象时,可以通过meta参数的cookiejar字段指定所要使用的CookieJar,如:
# 账号account1 发送的请求
Request(url1, meta={'cookiejar': 'account1'})
Request(url2, meta={'cookiejar': 'account1'})
Request(url3, meta={'cookiejar': 'account1'})
...
# 账号account2 发送的请求
Request(url1, meta={'cookiejar': 'account2'})
Request(url2, meta={'cookiejar': 'account2'})
Request(url3, meta={'cookiejar': 'account2'})
...
● process_request方法
处理每一个待发送的Request对象,尝试从request.meta['cookiejar']获取用户指定使用的CookieJar,如果用户未指定,就使用默认的CookieJar(self.jars[None])。调用self._get_request_cookies方法获取发送请求request应携带的Cookie信息,填写到HTTP请求头部。
● process_response方法
处理每一个Response对象,依然通过request.meta['cookiejar']获取CookieJar对象,调用extract_cookies方法将HTTP响应头部中的Cookie信息保存到CookieJar对象中。
另外需要注意的是,这里的CookieJar是scrapy.http.cookies.CookieJar,而10.4.1小节中的CookieJar是标准库中的http.cookiejar.CookieJar,它们是不同的类,前者对后者进行了包装,两者可以相互转化。
10.4.3 实现BrowserCookiesMiddleware
CookiesMiddleware自动处理Cookie的特性给用户提供了便利,但它不能使用浏览器的Cookie,我们可以利用browsercookie对CookiesMiddleware进行改良,实现一个能使用浏览器Cookie的中间件,代码如下:
import browsercookie
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
class BrowserCookiesMiddleware(CookiesMiddleware):
def __init__(self, debug=False):
super().__init__(debug)
self.load_browser_cookies()
def load_browser_cookies(self):
# 加载Chrome 浏览器中的Cookie
jar = self.jars['chrome']
chrome_cookiejar = browsercookie.chrome()
for cookie in chrome_cookiejar:
jar.set_cookie(cookie)
# 加载Firefox 浏览器中的Cookie
jar = self.jars['firefox']
firefox_cookiejar = browsercookie.firefox()
for cookie in firefox_cookiejar:
jar.set_cookie(cookie)
了解了CookiesMiddleware的工作原理,便不难理解BrowserCookiesMiddleware的实现了,其核心思想是:在构造BrowserCookiesMiddleware对象时,使用browsercookie将浏览器中的Cookie提取,存储到CookieJar字典self.jars中,解释代码如下:
● 继承CookiesMiddleware并实现构造器方法,在构造器方法中先调用基类的构造器方法,然后调用self.load_browser_cookies方法加载浏览器Cookie。
● 在load_browser_cookies方法中,使用self.jars['chrome']和self.jars['firefox']从默认字典中获得两个CookieJar对象,然后调用browsercookie的chrome和firefox方法,分别获取两个浏览器中的Cookie,将它们填入各自的CookieJar对象中。
10.4.4 爬取知乎个人信息
下面通过一个例子展示BrowserCookiesMiddleware的使用,知乎网是国内最流行的问答网站,我们在Chrome浏览器登录知乎后,可以访问如图10-12所示的用户个人信息页面。
接下来,我们使用BrowserCookiesMiddleware爬取这个登录后才能访问的页面,提取用户的“姓名”和“个性域名”信息。
图10-12
首先创建Scrapy项目,取名为browser_cookie:
$ scrapy startproject browser_cookie
然后,将BrowserCookiesMiddleware源码复制到该项目下的middlewares.py中,并在配置文件settings.py中添加如下配置:
# 伪装成常规浏览器
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) Chrome/42.0.2311.90 Safari/537.36'
# 用BrowserCookiesMiddleware 替代CookiesMiddleware 启用前者,关闭后者
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': None,
'browser_cookie.middlewares.BrowserCookiesMiddleware': 701,
}
由于需求非常简单,因此不再编写Spider,直接在scrapy shell环境中进行演示。注意,为了使用项目中的配置,需要在项目目录下启动scrapy shell命令:
$ scrapy shell
...
>>> from scrapy import Request
>>> url = 'https://www.zhihu.com/settings/profile'
>>> fetch(Request(url, meta={'cookiejar': 'chrome'}))
...
>>> view(response)
调用view函数后,在浏览器中可看到如图10-13所示的页面。
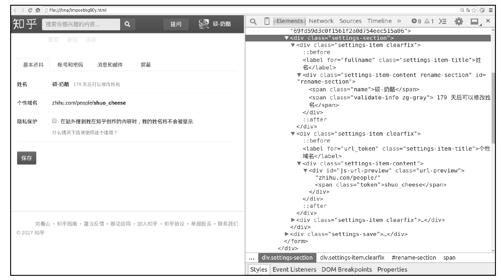
图10-13
结果表明,BrowserCookiesMiddleware按我们所预期的工作了,Scrapy爬虫使用浏览器的Cookie成功地获取了一个需要用户登录后才能访问的页面。
最后,提取页面中的“姓名”和“个性域名”信息:
>>> response.css('div#rename-section span.name::text').extract_first()
'硕-奶酪'
>>> response.xpath('string(//div[@id="js-url-preview"])').extract_first()
'zhihu.com/people/shuo_cheese'
到此,使用浏览器Cookie登录的案例展示完毕。
10.5 本章小结
本章我们学习了Scrapy爬虫模拟登录网站的相关内容,首先介绍了网站登录的原理,并讲解如何使用FormRequest提交登录表单模拟登录,然后讲解识别验证码的3种方法,最后介绍如何使用浏览器Cookie直接登录,并实现了一个下载中间件BrowserCookiesMiddleware。










