预计阅读本页时间:-

第11章
爬取动态页面
在之前章节中,我们爬取的都是静态页面中的信息,静态页面的内容始终不变,爬取相对容易,但在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难,这一章来学习如何爬取动态页面。
先来看一个简单的动态页面的例子,在浏览器中打开http://quotes.toscrape.com/js,显示如图11-1所示。
页面中有10条名人名言,每一条都包含在一个<div class="quote">元素中,如图11-2所示。现在,我们在scrapy shell环境下尝试爬取页面中的名人名言:
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
$ scrapy shell http://quotes.toscrape.com/js/
...
>>> response.css('div.quote')
[]
从结果看出,爬取失败了,在页面中没有找到任何包含名人名言的<div class="quote">元素。这些<div class="quote">就是动态内容,从服务器下载的页面中并不包含它们(所以我们爬取失败),浏览器执行了页面中的一段JavaScript代码后,它们才被生成出来,如图11-3所示。

图11-1
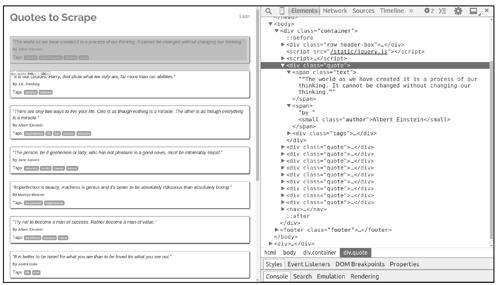
图11-2

图11-3
图中的JavaScript代码如下:
var data = [
{
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
],
"author": {
"name": "Albert Einstein",
"goodreads_link": "/author/show/9810.Albert_Einstein",
"slug": "Albert-Einstein"
},
"text": "\u201cThe world as we have created it is a process of our thinking. \
It cannot be changed without changing our thinking.\u201d"
},
{
"tags": [
"abilities",
"choices"
],
"author": {
"name": "J.K. Rowling",
"goodreads_link": "/author/show/1077326.J_K_Rowling",
"slug": "J-K-Rowling"
},
"text": "\u201cIt is our choices, Harry, that show what we truly are, \
far more than our abilities.\u201d"
},
... 省略部分内容 ...
{
"tags": [
"humor",
"obvious",
"simile"
],
"author": {
"name": "Steve Martin",
"goodreads_link": "/author/show/7103.Steve_Martin",
"slug": "Steve-Martin"
},
"text": "\u201cA day without sunshine is like, you know, night.\u201d"
}
];
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("<div class='quote'><span class='text'>" +
d['text'] + "</span><span>by <small class='author'>" +
d['author']['name'] + "</small></span><div class='tags'>Tags: " +
tags + "</div></div>");
}
阅读代码可以了解页面动态生成的细节,所有名人名言信息被保存在数组data中,最后的for循环迭代data中的每项信息,使用document.write生成每条名人名言对应的<div class="quote">元素。
上面是动态网页中最简单的一个例子,数据被硬编码于JavaScript代码中,实际中更常见的是JavaScript通过HTTP请求跟网站动态交互获取数据(AJAX),然后使用数据更新HTML页面。爬取此类动态网页需要先执行页面中的JavaScript代码渲染页面,再进行爬取。下面我们介绍如何使用JavaScript渲染引擎渲染页面。
11.1 Splash渲染引擎
Splash是Scrapy官方推荐的JavaScript渲染引擎,它是使用Webkit开发的轻量级无界面浏览器,提供基于HTTP接口的JavaScript渲染服务,支持以下功能:
● 为用户返回经过渲染的HTML页面或页面截图。
● 并发渲染多个页面。
● 关闭图片加载,加速渲染。
● 在页面中执行用户自定义的JavaScript代码。
● 执行用户自定义的渲染脚本(lua),功能类似于PhantomJS。
首先安装Splash,在linux下使用docker安装十分方便:
$ sudo apt-get install docker
$ sudo docker pull scrapinghub/splash
安装完成后,在本机的8050和8051端口开启Splash服务:
$ sudo docker run -p 8050:8050 -p 8051:8051 scrapinghub/splash
[-] Log opened.
[-] Splash version: 2.1
[-] Qt 5.5.1, PyQt 5.5.1, WebKit 538.1, sip 4.17, Twisted 16.1.1, Lua 5.2
[-] Python 3.5 (default, Oct 14 2015, 20:28:29) [GCC 4.8.4]
[-] Open files limit: 524288
[-] Open files limit increased from 524288 to 1048576
[-] Xvfb is started: ['Xvfb', ':1', '-screen', '0', '1024x768x24']
[-] proxy profiles support is enabled, proxy profiles path: /etc/splash/proxy-profiles
[-] verbosity=1
[-] slots=50
[-] argument_cache_max_entries=500
[-] Web UI: enabled, Lua: enabled (sandbox: enabled)
[-] Site starting on 8050
[-] Starting factory
Splash功能丰富,包含多个服务端点,由于篇幅有限,这里只介绍其中两个最常用的端点:
● render.html
提供JavaScript页面渲染服务。
● execute
执行用户自定义的渲染脚本(lua),利用该端点可在页面中执行JavaScript代码。
Splash文档地址:http://splash.readthedocs.io/en/latest/api.html。
11.1.1 render.html端点
JavaScript页面渲染服务是Splash中最基础的服务,请看表11-1中列出的文档。
表11-1

render.html端点支持的参数如表11-2所示。
表11-2
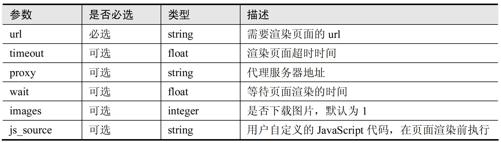
这里仅列出部分常用参数,详细内容参见官方文档。
下面是使用requests库调用render.html端点服务对页面http://quotes.toscrape.com/js/进行渲染的示例代码。
>>> import requests
>>> from scrapy.selector import Selector
>>> splash_url = 'http://localhost:8050/render.html'
>>> args = {'url': 'http://quotes.toscrape.com/js', 'timeout': 5, 'image': 0}
>>> response = requests.get(splash_url, params=args)
>>> sel = Selector(response)
>>> sel.css('div.quote span.text::text').extract() #提取所有名人名言
['“The world as we have created it is a process of our thinking. It cannot be changed without changing
our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as
though everything is a miracle.”',
'“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably
stupid.”',
"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely
boring.”",
'“Try not to become a man of success. Rather become a man of value.”',
'“It is better to be hated for what you are than to be loved for what you are not.”',
"“I have not failed. I've just found 10,000 ways that won't work.”",
"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”",
'“A day without sunshine is like, you know, night.”']
在上述代码中,依据文档中的描述设置参数url、timeout、images,然后发送HTTP请求到服务接口地址。从运行结果看出,页面渲染成功,我们爬取到了页面中的10条名人名言。
11.1.2 execute端点
在爬取某些页面时,我们想在页面中执行一些用户自定义的JavaScript代码,例如,用JavaScript模拟点击页面中的按钮,或调用页面中的JavaScript函数与服务器交互,利用Splash的execute端点提供的服务可以实现这样的功能。请看表11-3中的文档。
表11-3

execute端点支持的参数如表11-4所示。
表11-4

我们可以将execute端点的服务看作一个可用lua语言编程的浏览器,功能类似于PhantomJS。使用时需传递一个用户自定义的lua脚本给Splash,该lua脚本中包含用户想要模拟的浏览器行为,例如:
● 打开某url地址的页面
● 等待页面加载及渲染
● 执行JavaScript代码
● 获取HTTP响应头部
● 获取Cookie
下面是使用requests库调用execute端点服务的示例代码。
>>> import requests
>>> import json
>>> lua_script = '''
... function main(splash)
... splash:go("http://example.com") --打开页面
... splash:wait(0.5) --等待加载
... local title = splash:evaljs("document.title") --执行js代码获取结果
... return {title=title} --返回json 形式的结果
... end
... '''
>>> splash_url = 'http://localhost:8050/execute'
>>> headers = {'content-type': 'application/json'}
>>> data = json.dumps({'lua_source': lua_script})
>>> response = requests.post(splash_url, headers=headers, data=data)
>>> response.content
b'{"title": "Example Domain"}'
>>> response.json()
{'title': 'Example Domain'}
用户自定义的lua脚本中必须包含一个main函数作为程序入口,main函数被调用时会传入一个splash对象(lua中的对象),用户可以调用该对象上的方法操纵Splash。例如,在上面的例子中,先调用go方法打开某页面,再调用wait方法等待页面渲染,然后调用evaljs方法执行一个JavaScript表达式,并将结果转化为相应的lua对象,最终Splash根据main函数的返回值构造HTTP响应返回给用户,main函数的返回值可以是字符串,也可以是lua中的表(类似Python字典),表会被编码成json串。
接下来,看一下splash对象常用的属性和方法。
● splash.args属性
用户传入参数的表,通过该属性可以访问用户传入的参数,如splash.args.url、splash.args.wait。
● splash.js_enabled属性
用于开启/禁止JavaScript渲染,默认为true。
● splash.images_enabled属性
用于开启/禁止图片加载,默认为true。
● splash:go方法
splash:go{url, baseurl=nil, headers=nil, http_method="GET", body=nil, formdata=nil}
类似于在浏览器中打开某url地址的页面,页面所需资源会被加载,并进行JavaScript渲染,可以通过参数指定HTTP请求头部、请求方法、表单数据等。
● splash:wait方法
splash:wait{time, cancel_on_redirect=false, cancel_on_error=true}等待页面渲染,time参数为等待的秒数。
● splash:evaljs方法
splash:evaljs(snippet)
在当前页面下,执行一段JavaScript代码,并返回最后一句表达式的值。
● splash:runjs方法
splash:runjs(snippet)
在当前页面下,执行一段JavaScript代码,与evaljs方法相比,该函数只执行JavaScript代码,不返回值。
● splash:url方法
splash:url()
获取当前页面的url。
● splash:html方法
splash:html()
获取当前页面的HTML文本。
● splash:get_cookies方法
splash:get_cookies()
获取全部Cookie信息.
11.2 在Scrapy中使用Splash
掌握了Splash渲染引擎的基本使用后,我们继续学习如何在Scrapy中调用Splash服务,Python库的scrapy-splash是非常好的选择。
使用pip安装scrapy-splash:
$ pip install scrapy-splash
在项目环境中讲解scrapy-splash的使用,创建一个Scrapy项目,取名为splash_examples:
$ scrapy startproject splash_examples
首先在项目配置文件settings.py中对scrapy-splash进行配置,添加内容如下:
# Splash服务器地址
SPLASH_URL = 'http://localhost:8050'
# 开启Splash的两个下载中间件并调整HttpCompressionMiddleware的次序
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 设置去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 用来支持cache_args(可选)
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
编写Spider代码过程中,使用scrapy_splash调用Splash服务非常简单,scrapy_splash中定义了一个SplashRequest类,用户只需使用scrapy_splash.SplashRequest(替代scrapy.Request)提交请求即可。下面是SplashRequest构造器方法中的一些常用参数。
● url
与scrapy.Request中的url相同,也就是待爬取页面的url(注意,不是Splash服务器地址)。
● headers
与scrapy.Request中的headers相同。
● cookies
与scrapy.Request中的cookies相同。
● args
传递给Splash的参数(除url以外),如wait、timeout、images、js_source等。
● cache_args
如果args中的某些参数每次调用都重复传递并且数据量较大(例如一段JavaScript代码),此时可以把该参数名填入cache_args列表中,让Splash服务器缓存该参数,如SplashRequest(url, args = {'js_source': js, 'wait': 0.5}, cache_args = ['js_source'])。
● endpoint
Splash服务端点,默认为'render.html',即JavaScript页面渲染服务,该参数可以设置为'render.json'、'render.har'、'render.png'、'render.jpeg'、'execute'等,有些服务端点的功能我们没有讲解,详细内容可以查阅文档。
● splash_url
Splash服务器地址,默认为None,即使用配置文件中SPLASH_URL的地址。
现在,大家已经对如何在Scrapy中使用Splash渲染引擎爬取动态页面有了一定了解,接下来我们在已经配置了Splash使用环境的splash_examples项目中完成两个实战项目。
11.3 项目实战:爬取toscrape中的名人名言
11.3.1 项目需求
爬取网站http://quotes.toscrape.com/js中的名人名言信息。
11.3.2 页面分析
该网站的页面已在本章开头部分分析过,大家可以回头看相关内容。
11.3.3 编码实现
首先,在splash_examples项目目录下使用scrapy genspider命令创建Spider:
scrapy genspider quotes quotes.toscrape.com
在这个案例中,我们只需使用Splash的render.html端点渲染页面,再进行爬取即可实现QuotesSpider,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/js/']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, args={'images': 0, 'timeout': 3})
def parse(self, response):
for sel in response.css('div.quote'):
quote = sel.css('span.text::text').extract_first()
author = sel.css('small.author::text').extract_first()
yield {'quote': quote, 'author': author}
href = response.css('li.next > a::attr(href)').extract_first()
if href:
url = response.urljoin(href)
yield SplashRequest(url, args={'images': 0, 'timeout': 3})
上述代码中,使用SplashRequest提交请求,在SplashRequest的构造器中无须传递endpoint参数,因为该参数默认值便是'render.html'。使用args参数禁止Splash加载图片,并设置渲染超时时间。
运行爬虫,观察结果:
$ scrapy crawl quotes -o quotes.csv
...
$ cat -n quotes.csv
1 quote,author
2 “The world as we have created it is a process of our thinking. It cannot be changed without
changing our thinking.”,Albert Einstein
3 "“It is our choices, Harry, that show what we truly are, far more than our abilities.”",J.K.
Rowling
4 “There are only two ways to live your life. One is as though nothing is a miracle. The other is
as though everything is a miracle.”,Albert Einstein
5 "“The person, be it gentleman or lady, who has not pleasure in a good novel, must be
intolerably stupid.”",Jane Austen
6 "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than
absolutely boring.”",Marilyn Monroe
7 “Try not to become a man of success. Rather become a man of value.”,Albert Einstein
8 “It is better to be hated for what you are than to be loved for what you are not.”,André Gide
9 "“I have not failed. I've just found 10,000 ways that won't work.”",Thomas A. Edison
10 “A woman is like a tea bag; you never know how strong it is until it's in hot water.”,Eleanor
Roosevelt
...
91 "“I believe in Christianity as I believe that the sun has risen: not only because I see it, but
because by it I see everything else.”",C.S. Lewis
92 "“The truth."" Dumbledore sighed. ""It is a beautiful and terrible thing, and should therefore
be treated with great caution.”",J.K. Rowling
93 "“I'm the one that's got to die when it's time for me to die, so let me live my life the way I
want to.”",Jimi Hendrix
94 “To die will be an awfully big adventure.”,J.M. Barrie
95 “It takes courage to grow up and become who you really are.”,E.E. Cummings
96 “But better to get hurt by the truth than comforted with a lie.”,Khaled Hosseini
97 “You never really understand a person until you consider things from his point of view...
Until you climb inside of his skin and walk around in it.”,Harper Lee
98 "“You have to write the book that wants to be written. And if the book will be too difficult for
grown-ups, then you write it for children.”",Madeleine L'Engle
99 “Never tell the truth to people who are not worthy of it.”,Mark Twain
100 "“A person's a person, no matter how small.”",Dr. Seuss
101 "“... a mind needs books as a sword needs a whetstone, if it is to keep its edge.”",George R.R.
Martin
运行结果显示,我们成功爬取了10个页面中的100条名人名言。
11.4 项目实战:爬取京东商城中的书籍信息
11.4.1 项目需求
爬取京东商城中所有Python书籍的名字和价格信息。
11.4.2 页面分析
图11-4所示为在京东网站(http://www.jd.com)的书籍分类下搜索Python关键字得到的页面。
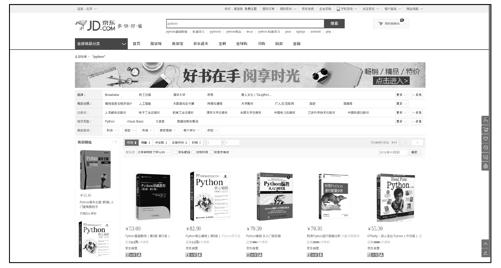
图11-4
结果有很多页,在每一个书籍列表页面中可以数出有60本书,但我们在scrapy shell中爬取该页面时遇到了问题,仅在页面中找到了30本书,少了30本,代码如下:
$ scrapy shell
...
>>> url = 'https://search.jd.com/Search?keyword=python&enc=utf-8&book=y&wq=python'
>>> fetch(url)
...
>>> len(response.css('ul.gl-warp > li'))
30
原来页面中的60本书不是同时加载的,开始只有30本书,当我们使用鼠标滚轮滚动到页面下方某位置时,后30本书才由JavaScript脚本加载,通过实验可以验证这个说法,实验流程如下:
(1)页面刚加载时,在Chrome开发者工具的console中用jQuery代码查看当前有多少本书,此时为30。
(2)之后滚动鼠标滚轮到某一位置时,可以看到JavaScript发送HTTP请求和服务器交互(XHR)。
(3)然后用jQuery代码查看当前有多少本书,已经变成了60,如图11-5所示。
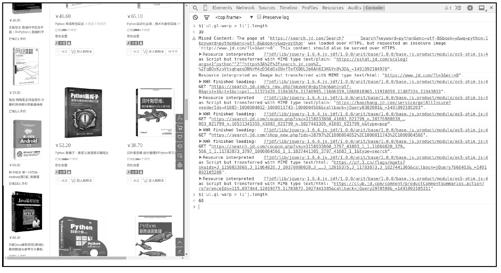
图11-5
既然如此,爬取这个页面时,可以先执行一段JavaScript代码,将滚动条拖到页面下方某位置,触发加载后30本书的事件,在开发者工具的console中进行实验,用document.getElementsByXXX方法随意选中页面下方的某元素,比如“下一页”按钮所在的<div>元素,然后在该元素对象上调用scrollIntoView(true)完成拖曳动作,此时查看书籍数量,变成了60,这个解决方案是可行的。图11-6所示为实验过程。
爬取一个页面的问题解决了,再来研究如何从页面中找到下一页的url地址。
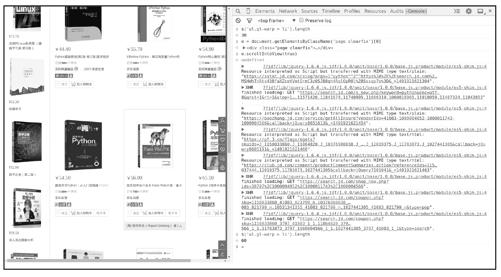
图11-6
如图11-7所示,下一页链接的href属性并不是一个url,而在其onclick属性中包含了一条JavaScript代码,单击“下一页”按钮时会调用函数SEARCH.page(n, true)。虽然可以用Splash执行函数来跳转到下一页,但还是很麻烦,经观察发现,每个页面url的差异仅在于page参数不同,第一页page=1,第2页page=3,第3页page=5……以2递增,并且页面中还包含商品总数信息。因此,我们可以推算出所有页面的url。
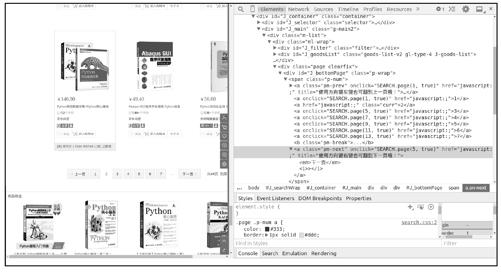
图11-7
11.4.3 编码实现
首先,在splash_examples项目目录下使用scrapy genspider命令创建Spider类:
scrapy genspider jd_book search.jd.com
经上述分析,在爬取每一个书籍列表页面时都需要执行一段JavaScript代码,以让全部书籍加载,因此选用execute端点完成该任务,实现JDBookSpider代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy_splash import SplashRequest
lua_script = '''
function main(splash)
splash:go(splash.args.url)
splash:wait(2)
splash:runjs("document.getElementsByClassName('page')[0].scrollIntoView(true)")
splash:wait(2)
return splash:html()
end
'''
class JDBookSpider(scrapy.Spider):
name = "jd_book"
allowed_domains = ["search.jd.com"]
base_url = 'https://search.jd.com/Search?keyword=python&enc=utf-8&book=y&wq=python'
def start_requests(self):
# 请求第一页,无须js渲染
yield Request(self.base_url, callback=self.parse_urls, dont_filter=True)
def parse_urls(self, response):
# 获取商品总数,计算出总页数
total = int(response.css('span#J_resCount::text').extract_first())
pageNum = total // 60 + (1 if total % 60 else 0)
# 构造每页的url,向Splash的execute 端点发送请求
foriin range(pageNum):
url = '%s&page=%s' % (self.base_url, 2 * i + 1)
yield SplashRequest(url,
endpoint='execute',
args={'lua_source': lua_script},
cache_args=['lua_source'])
def parse(self, response):
# 获取一个页面中每本书的名字和价格
for sel in response.css('ul.gl-warp.clearfix > li.gl-item'):
yield {
'name': sel.css('div.p-name').xpath('string(.//em)').extract_first(),
'price': sel.css('div.p-price i::text').extract_first(),
}
解释上述代码如下:
● start_requests方法
start_requests提交对第一个页面的请求,这个页面不需要渲染,因为我们只想从中获取页面总数,使用scrapy.Request提交请求,并指定parse_urls作为解析函数。
● parse_urls方法
从第一个页面中提取商品总数,用其计算页面总数,之后按照前面分析出的页面url规律构造每一个页面的url。这些页面都是需要渲染的,使用SplashRequest提交请求,除了渲染页面以外,还需要执行一段JavaScript代码(为了加载后30本书),因此使用Splash的execute端点将endpoint参数置为'execute'。通过args参数的lua_source字段传递我们要执行的lua脚本,由于爬取每个页面时都要执行该脚本,因此可以使用cache_args参数将该脚本缓存到Splash服务器。
● parse方法
一个页面中提取60本书的名字和价格信息,相关内容大家早已熟悉,不再赘述。
● lua_script字符串
自定义的lua脚本,其中的逻辑很简单:
打开页面→等待渲染→执行js触发数据加载(后30本书)→等待渲染→返回html。
另外,京东服务器程序会对请求头部中的User-Agent字段进行检测,因此需要在配置文件settings.py中设置USER_AGENT,伪装成常规浏览器:
# 伪装成常规浏览器
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)'
编码和配置的工作已经完成了,运行爬虫并观察结果:
$ scrapy crawl jd_book -o books.csv
...
$ cat -n books.scv
1 name,price
2 教孩子学编程 Python语言版,59.00
3 Python机器学习 预测分析核心算法,46.90
4 Python机器学习 预测分析核心算法 9787115433732 [美] Michael,52.44
5 Python数据分析实战 9787115432209,39.50
6 数据科学实战手册 R+Python 9787115426758,39.50
7 Python编程 从入门到实践,89.00
8 Python可以这样学,69.00
9 Python游戏编程快速上手,47.20
10 Python性能分析与优化,45.00
...
2932 Python语言在Abaqus 中的应用(附CD-ROM光盘1 张),38.40
2933 Python绝技 运用Python成为*级黑客 运用Python成为 级黑客 书籍,46.50
2934 趣学Python编程,42.70
2935 零基础学Python(图文版),65.50
2936 Python程序设计入门到实战,65.50
2937 计算机科学丛书:Python语言程序设计,74.60
2938 面向ArcGIS的Python脚本编程,41.00
2939 Python算法教程 书籍,40.60
2940 Python基础教程+利用Python进行数据分析 Python学习套装 共两册,136.20
2941 包邮 量化投资 以Python 为工具 Python语言处理数据Python金融 量化投,65.80
结果显示,我们成功爬取到了2940本书籍的信息。
11.5 本章小结
本章学习了爬取动态页面的相关知识,首先带大家了解了动态页面的实现原理,然后介绍了页面渲染引擎Splash,并详细讲解了其中render.html和execute两个服务端点的使用,最后通过两个案例展示了在Scrapy爬虫中如何利用Splash服务爬取动态页面的内容。










