预计阅读本页时间:-

第13章
使用HTTP代理
大家可能都有过给浏览器设置HTTP代理的经验,HTTP代理服务器可以比作客户端与Web服务器(网站)之间的一个信息中转站,客户端发送的HTTP请求和Web服务器返回的HTTP响应通过代理服务器转发给对方,如图13-1所示。
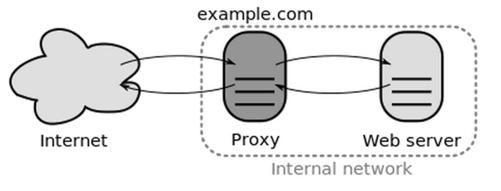
图13-1
爬虫程序在爬取某些网站时也需要使用代理,例如:
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
● 由于网络环境因素,直接爬取速度太慢,使用代理提高爬取速度。
● 某些网站对用户的访问速度进行限制,爬取过快会被封禁ip,使用代理防止被封禁。
● 由于地方法律或政治原因,某些网站无法直接访问,使用代理绕过访问限制。
这一章我们来学习Scrapy爬虫如何使用代理进行爬取。
13.1 HttpProxyMiddleware
Scrapy内部提供了一个下载中间件HttpProxyMiddleware,专门用于给Scrapy爬虫设置代理。
13.1.1 使用简介
HttpProxyMiddleware默认便是启用的,它会在系统环境变量中搜索当前系统代理(名字格式为xxx_proxy的环境变量),作为Scrapy爬虫使用的代理。
假设我们现在有两台在云上搭建好的代理服务器:
http://116.29.35.201:8118
http://197.10.171.143:8118
为本机的Scrapy爬虫分别设置发送HTTP和HTTPS请求时所使用的代理,只需在bash中添加环境变量:
$ export http_proxy="http://116.29.35.201:8118" # 为HTTP请求设置代理
$ export https_proxy="http://197.10.171.143:8118" # 为HTTPS请求设置代理
配置完成后,Scrapy爬虫将会使用上面指定的代理下载页面,我们可以通过以下实验进行验证。
利用网站http://httpbin.org提供的服务可以窥视我们所发送的HTTP(S)请求,如请求源IP地址、请求头部、Cookie信息等。图13-2展示了该网站各种服务的API地址。
访问http(s)://httpbin.org/ip将返回一个包含请求源IP地址信息的json串,在scrapy shell中访问该url,查看请求源IP地址:

图13-2
$ scrapy shell
...
>>> import json
>>> fetch(scrapy.Request('http://httpbin.org/ip')) # 发送HTTP请求
[scrapy] DEBUG: Crawled (200) (referer: None)
>>> json.loads(response.text)
{'origin': '116.29.35.201'}
>>> fetch(scrapy.Request('https://httpbin.org/ip')) # 发送HTTPS请求
[scrapy] DEBUG: Crawled (200) (referer: None)
>>> json.loads(response.text)
{'origin': '197.10.171.143'}
在上述实验中,分别以HTTP和HTTPS发送请求,使用json模块对响应结果进行解析,读取请求源IP地址(origin字段),其值正是代理服务器的IP。由此证明,Scrapy爬虫使用了我们指定的代理。
上面我们使用的是无须身份验证的代理服务器,还有一些代理服务器需要用户提供账号、密码进行身份验证,验证成功后才提供代理服务,使用此类代理时,可按以下格式配置:
$ export http_proxy="http://liushuo:12345678@113.24.36.24:7777"
13.1.2 源码分析
虽然使用HttpProxyMiddleware很简单,但大家最好对其工作原理有所了解,以下是HttpProxyMiddleware的源码:
import base64
from six.moves.urllib.request import getproxies, proxy_bypass
from six.moves.urllib.parse import unquote
try:
from urllib2 import _parse_proxy
except ImportError:
from urllib.request import _parse_proxy
from six.moves.urllib.parse import urlunparse
from scrapy.utils.httpobj import urlparse_cached
from scrapy.exceptions import NotConfigured
from scrapy.utils.python import to_bytes
class HttpProxyMiddleware(object):
def __init__(self, auth_encoding='latin-1'):
self.auth_encoding = auth_encoding
self.proxies = {}
for type, url in getproxies().items():
self.proxies[type] = self._get_proxy(url, type)
if not self.proxies:
raise NotConfigured
@classmethod
def from_crawler(cls, crawler):
auth_encoding = crawler.settings.get('HTTPPROXY_AUTH_ENCODING')
return cls(auth_encoding)
def _get_proxy(self, url, orig_type):
proxy_type, user, password, hostport = _parse_proxy(url)
proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
if user:
user_pass = to_bytes(
'%s:%s' % (unquote(user), unquote(password)),
encoding=self.auth_encoding)
creds = base64.b64encode(user_pass).strip()
else:
creds = None
return creds, proxy_url
def process_request(self, request, spider):
# ignore if proxy is already set
if 'proxy' in request.meta:
return
parsed = urlparse_cached(request)
scheme = parsed.scheme
# 'no_proxy' is only supported by http schemes
if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):
return
if scheme in self.proxies:
self._set_proxy(request, scheme)
def _set_proxy(self, request, scheme):
creds, proxy = self.proxies[scheme]
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
分析代码如下:
● __init__方法
在HttpProxyMiddleware的构造器中,使用Python标准库urllib中的getproxies函数在系统环境变量中搜索系统代理的相关配置(变量名格式为[协议]_proxy的变量),调用self._get_proxy方法解析代理配置信息,并将其返回结果保存到self.proxies字典中,如果没有找到任何代理配置,就抛出NotConfigured异常,HttpProxyMiddleware被弃用。
● _get_proxy方法
解析代理配置信息,返回身份验证信息(后面讲解)以及代理服务器url。
● process_request方法
处理每一个待发送的请求,为没有设置过代理的请求(meta属性不包含proxy字段的请求)调用self._set_proxy方法设置代理。
● _set_proxy方法
为一个请求设置代理,以请求的协议(HTTP或HTTPS)作为键,从代理服务器信息字典self.proxies中选择代理,赋给request.meta的proxy字段。对于需要身份验证的代理服务器,添加HTTP头部Proxy-Authorization,其值是在_get_proxy方法中计算得到的。
经分析得知,在Scrapy中为一个请求设置代理的本质就是将代理服务器的url填写到request.meta['proxy']。
13.2 使用多个代理
利用HttpProxyMiddleware为爬虫设置代理时,对于一种协议(HTTP或HTTPS)的所有请求只能使用一个代理,如果想使用多个代理,可以在构造每一个Request对象时,通过meta参数的proxy字段手动设置代理:
request1 = Request('http://example.com/1', meta={'proxy': 'http://166.1.34.21:7117'})
request2 = Request('http://example.com/2', meta={'proxy': 'http://177.2.35.21:8118'})
request3 = Request('http://example.com/3', meta={'proxy': 'http://188.3.36.21:9119'})
按照与之前相同的做法,在scrapy shell进行实验,验证代理是否被使用:
$ scrapy shell
...
>>> from scrapy import Request
>>> req = Request('http://httpbin.org/ip', meta={'proxy': 'http://116.29.35.201:8118'})
>>> fetch(req)
[scrapy] DEBUG: Crawled (200) (referer: None)
>>> json.loads(response.text)
{'origin': '116.29.35.201'}
>>> req = Request('https://httpbin.org/ip', meta={'proxy': 'http://197.10.171.143:8118'})
>>> fetch(req)
[scrapy] DEBUG: Crawled (200) (referer: None)
>>> json.loads(response.text)
{'origin': '197.10.171.143'}
结果表明,Scrapy爬虫同样使用了指定的代理服务器。
使用手动方式设置代理时,如果使用的代理需要身份验证,还需要通过HTTP头部的Proxy-Authorization字段传递包含用户账号和密码的身份验证信息。可以参考HttpProxyMiddleware._get_proxy中的相关实现,按以下过程生成身份验证信息:
(1)将账号、密码拼接成形如'user:passwd'的字符串s1。
(2)按代理服务器要求对s1进行编码(如utf8),生成s2。
(3)再对s2进行Base64编码,生成s3。
(4)将s3拼接到固定字节串b'Basic '后面,得到最终的身份验证信息。
示例代码如下:
>>> from scrapy import Request
>>> import base64
>>> req = Request('http://httpbin.org/ip', meta={'proxy': 'http://116.29.35.201:8118'})
>>> user = 'liushuo'
>>> passwd = '12345678'
>>> user_passwd = ('%s:%s' % (user, passwd)).encode('utf8')
>>> user_passwd
b'liushuo:12345678'
>>> req.headers['Proxy-Authorization'] = b'Basic ' + base64.b64encode(user_passwd)
>>> fetch(req)
...
13.3 获取免费代理
现在,我们了解了如何为Scrapy爬虫设置代理,接下来的一个话题便是如何获取代理服务器。如果你感觉购买云服务器(亚马逊云或阿里云服务器等)自行搭建代理服务器的成本太高(但可靠、可控),那么可以通过google或baidu找到一些提供免费代理服务器信息的网站,例如:
http://proxy-list.org(国外)
https://free-proxy-list.net(国外)
http://www.xicidaili.com
http://www.proxy360.cn
http://www.kuaidaili.com
以http://www.xicidaili.com为例,图13-3所示为该网站“国内高匿代理”分类下的页面。
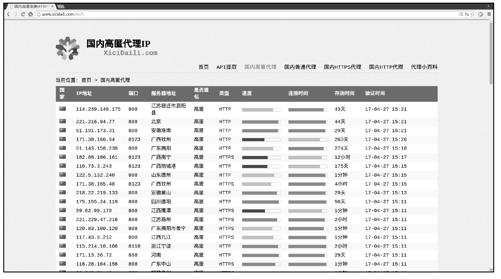
图13-3
从中可以看出,该网站提供了大量的免费代理服务器信息,如果只需要少量的代理,从中选择几个就可以了,不过通常直觉告诉我们“多多益善”。接下来编写爬虫,爬取“国内高匿代理”分类下前3页的所有代理服务器信息,并验证每个代理是否可用。
创建Scrapy项目,取名为proxy_example:
$ scrapy startproject proxy_example
该网站会检测用户发送的HTTP请求头部中的User-Agent字段,因此我们需要伪装成某种常规浏览器,在配置文件添加如下代码:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/41.0.2272.76'
实现XiciSpider爬取代理服务器信息,并过滤不可用代理,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
class XiciSpider(scrapy.Spider):
name = "xici_proxy"
allowed_domains = ["www.xicidaili.com"]
def start_requests(self):
#爬取http://www.xicidaili.com/nn/前3 页
foriin range(1, 4):
yield Request('http://www.xicidaili.com/nn/%s' % i)
def parse(self, response):
for sel in response.xpath('//table[@id="ip_list"]/tr[position()>1]'):
# 提取代理的IP、port、scheme(http or https)
ip = sel.css('td:nth-child(2)::text').extract_first()
port = sel.css('td:nth-child(3)::text').extract_first()
scheme = sel.css('td:nth-child(6)::text').extract_first().lower()
# 使用爬取到的代理再次发送请求到http(s)://httpbin.org/ip,验证代理是否可用
url = '%s://httpbin.org/ip' % scheme
proxy = '%s://%s:%s' % (scheme, ip, port)
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
# 以下两个字段是传递给check_available 方法的信息,方便检测
'_proxy_scheme': scheme,
'_proxy_ip': ip,
}
yield Request(url, callback=self.check_available,
meta=meta, dont_filter=True)
def check_available(self, response):
proxy_ip = response.meta['_proxy_ip']
# 判断代理是否具有隐藏IP 功能
if proxy_ip == json.loads(response.text)['origin']:
yield {
'proxy_scheme': response.meta['_proxy_scheme'],
'proxy': response.meta['proxy'],
}
解释上述代码如下:
● 在start_requests方法中请求http://www.xicidaili.com/nn下的前3页,以parse方法作为页面解析函数。
● 在parse方法中提取一个页面中所有的代理服务器信息,这些代理未必都是可用的,因此使用爬取到的代理发送请求到http(s)://httpbin.org/ip验证其是否可用,以check_available方法作为页面解析函数。
● 能执行到check_available方法,意味着response对应请求所使用的代理是可用的。在check_available方法中,通过响应json串中的origin字段可以判断代理是否是匿名的(隐藏ip),返回匿名代理。
运行爬虫,将可用的代理服务器保存到json文件中,供其他程序使用:
$ scrapy crawl xici_proxy -o proxy_list.json
...
$ cat proxy_list.json
[
{"proxy": "http://110.73.10.37:8123", "proxy_scheme": "http"},
{"proxy": "http://171.38.142.24:8123", "proxy_scheme": "http"},
{"proxy": "http://111.155.124.84:8123", "proxy_scheme": "http"},
{"proxy": "http://203.88.210.121:138", "proxy_scheme": "http"},
{"proxy": "http://182.88.191.195:8123", "proxy_scheme": "http"},
{"proxy": "http://121.31.151.231:8123", "proxy_scheme": "http"},
{"proxy": "http://203.93.0.115:80", "proxy_scheme": "http"},
{"proxy": "http://222.85.39.29:808", "proxy_scheme": "http"},
{"proxy": "http://175.155.25.26:808", "proxy_scheme": "http"},
{"proxy": "http://111.155.124.72:8123", "proxy_scheme": "http"},
{"proxy": "http://122.5.81.153:8118", "proxy_scheme": "http"},
{"proxy": "https://171.37.153.24:8123", "proxy_scheme": "https"},
{"proxy": "http://110.73.1.68:8123", "proxy_scheme": "http"},
{"proxy": "http://122.228.179.178:80", "proxy_scheme": "http"},
{"proxy": "http://121.31.151.226:8123", "proxy_scheme": "http"},
{"proxy": "http://171.38.171.168:8123", "proxy_scheme": "http"},
{"proxy": "http://218.22.219.133:808", "proxy_scheme": "http"},
{"proxy": "https://171.38.130.188:8123", "proxy_scheme": "https"},
{"proxy": "http://111.155.116.219:8123", "proxy_scheme": "http"},
{"proxy": "http://121.31.149.209:8123", "proxy_scheme": "http"},
{"proxy": "http://60.169.78.218:808", "proxy_scheme": "http"},
{"proxy": "http://171.38.158.227:8123", "proxy_scheme": "http"},
{"proxy": "http://121.31.150.224:8123", "proxy_scheme": "http"},
{"proxy": "http://111.155.124.78:8123", "proxy_scheme": "http"},
{"proxy": "http://182.90.83.104:8123", "proxy_scheme": "http"}
]
如结果所示,我们成功获取到了20多个可用的免费代理。
13.4 实现随机代理
本章开始部分曾提到,某些网站为防止爬虫爬取会对接收到的请求进行监测,如果在短时间内接收到了来自同一IP的大量请求,就判定该IP的主机在使用爬虫程序爬取网站,因而将该IP封禁(拒绝请求)。爬虫程序可以使用多个代理对此类网站进行爬取,此时单位时间的访问量会被多个代理分摊,从而避免封禁IP。
下面我们基于HttpProxyMiddleware实现一个随机代理下载中间件。
在middlewares.py中实现RandomHttpProxyMiddleware,代码如下:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from collections import defaultdict
import json
import random
class RandomHttpProxyMiddleware(HttpProxyMiddleware):
def __init__(self, auth_encoding='latin-1', proxy_list_file=None):
if not proxy_list_file:
raise NotConfigured
self.auth_encoding = auth_encoding
# 分别用两个列表维护HTTP和HTTPS的代理,{'http': [...], 'https': [...]}
self.proxies = defaultdict(list)
# 从json文件中读取代理服务器信息,填入self.proxies
with open(proxy_list_file) as f:
proxy_list = json.load(f)
for proxy in proxy_list:
scheme = proxy['proxy_scheme']
url = proxy['proxy']
self.proxies[scheme].append(self._get_proxy(url, scheme))
@classmethod
def from_crawler(cls, crawler):
# 从配置文件中读取用户验证信息的编码
auth_encoding = crawler.settings.get('HTTPPROXY_AUTH_ENCODING', 'latain-1')
# 从配置文件中读取代理服务器列表文件(json)的路径
proxy_list_file = crawler.settings.get('HTTPPROXY_PROXY_LIST_FILE')
return cls(auth_encoding, proxy_list_file)
def _set_proxy(self, request, scheme):
# 随机选择一个代理
creds, proxy = random.choice(self.proxies[scheme])
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
解释上述代码如下:
● 仿照HttpProxyMiddleware构造器实现RandomHttpProxyMiddleware构造器,首先从代理服务器列表文件(配置文件中指定)中读取代理服务器信息,然后将它们按协议(HTTP或HTTPS)分别存入不同列表,由self.proxis字典维护。
● _set_proxy方法负责为每一个Request请求设置代理,覆写_set_proxy方法(覆盖基类方法)。对于每一个request,根据请求协议获取self.proxis中的代理服务器列表,然后从中随机抽取一个代理,赋值给request.meta['proxy']。
在配置文件settings.py中启用RandomHttpProxyMiddleware,并指定所要使用的代理服务器列表文件(json文件),添加代码如下:
DOWNLOADER_MIDDLEWARES = {
# 置于HttpProxyMiddleware(750)之前
'proxy_example.middlewares.RandomHttpProxyMiddleware': 745,
}
# 使用之前在http://www.xicidaili.com/网站爬取到的代理
HTTPPROXY_PROXY_LIST_FILE='proxy_list.json'
最后编写一个TestRandomProxySpider测试该中间件,重复向http(s)://httpbin.org/ip发送请求,根据响应中的请求源IP地址信息判断代理使用情况:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
class TestRandomProxySpider(scrapy.Spider):
name = "test_random_proxy"
def start_requests(self):
for _ in range(100):
yield Request('http://httpbin.org/ip', dont_filter=True)
yield Request('https://httpbin.org/ip', dont_filter=True)
def parse(self, response):
print(json.loads(response.text))
运行爬虫,观察输出:
$ scrapy crawl test_random_proxy
[scrapy] DEBUG: Crawled (200) <GET https://httpbin.org/ip> (referer: None)
{'origin': '171.38.130.188'}
[scrapy] DEBUG: Crawled (200) <GET http://httpbin.org/ip> (referer: None)
{'origin': '182.90.83.104'}
[scrapy] DEBUG: Crawled (200) <GET https://httpbin.org/ip> (referer: None)
{'origin': '171.38.130.188'}
[scrapy] DEBUG: Crawled (200) <GET http://httpbin.org/ip> (referer: None)
{'origin': '203.88.210.121'}
[scrapy] DEBUG: Crawled (200) <GET http://httpbin.org/ip> (referer: None)
{'origin': '203.88.210.121'}
...
结果表明,RandomHttpProxyMiddleware工作良好,Scrapy爬虫随机地使用了多个代理。
13.5 项目实战:爬取豆瓣电影信息
最后,我们来完成一个使用代理爬取的实战项目。豆瓣网的电影专栏是国内权威电影评分网站,其中包括海量影片信息,在浏览器中访问https://movie.douban.com,并选择一个分类(如“豆瓣高分”),可看到如图13-4所示的影片列表页面。
图13-4
单击其中一部影片,进入其页面(简称影片页面),如图13-5所示。
在影片页面中可以看到一部影片的基本信息,如导演、编剧、主演、类型等,我们可以编写爬虫在豆瓣电影中爬取大量影片信息。
图13-5
13.5.1 项目需求
爬取豆瓣电影中“豆瓣高分”分类下的所有影片信息,需要爬取一部影片的信息字段如下:
● 导演
● 编剧
● 主演
● 类型
● 制片国家/地区
● 语言
● 上映日期
● 片长
● 又名
由于豆瓣网对爬取速度做了限制,高速爬取可能会被封禁IP,因此使用代理进行爬取。
13.5.2 页面分析
首先分析影片列表页面,页面中的每一部电影都是通过JavaScript脚本加载的。单击页面最下方的“加载更多”,可以在Chrome开发者工具中捕获到jQuery发送的HTTP请求(加载更多影片),该请求返回了一个json串,如图13-6所示。
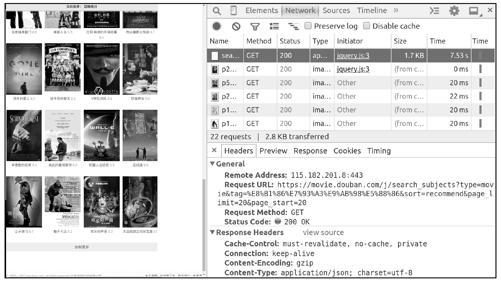
图13-6
复制图中请求的url,使用scrapy shell进行访问,查看其中json串的内容:
$ scrapy shell
'https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98
%E5%88%86&sort=recommend&page_limit=20&page_start=20'
...
>>> import json
>>> res = json.loads(response.body.decode('utf8'))
>>> res
{'subjects': [
{'cover': 'https://img1.doubanio.com/view/movie_poster_cover/lpst/public/p511146957.jpg',
'cover_x': 1538,
'cover_y': 2159,
'id': '1292001',
'is_beetle_subject': False,
'is_new': False,
'playable': False,
'rate': '9.2',
'title': '海上钢琴师',
'url': 'https://movie.douban.com/subject/1292001/'},
{'cover': 'https://img1.doubanio.com/view/movie_poster_cover/lpst/public/p2360940399.jpg',
'cover_x': 1500,
'cover_y': 2145,
'id': '25986180',
'is_beetle_subject': False,
'is_new': False,
'playable': False,
'rate': '8.2',
'title': '釜山行',
'url': 'https://movie.douban.com/subject/25986180/'},
{'cover': 'https://img1.doubanio.com/view/movie_poster_cover/lpst/public/p2404978988.jpg',
'cover_x': 703,
'cover_y': 1000,
'id': '26580232',
'is_beetle_subject': False,
'is_new': False,
'playable': False,
'rate': '8.7',
'title': '看不见的客人',
'url': 'https://movie.douban.com/subject/26580232/'},
...省略中间部分...
{'cover': 'https://img3.doubanio.com/view/movie_poster_cover/lpst/public/p1454261925.jpg',
'cover_x': 2181,
'cover_y': 3120,
'id': '6786002',
'is_beetle_subject': False,
'is_new': False,
'playable': False,
'rate': '9.1',
'title': '触不可及',
'url': 'https://movie.douban.com/subject/6786002/'},
{'cover': 'https://img3.doubanio.com/view/movie_poster_cover/lpst/public/p2411622136.jpg',
'cover_x': 1000,
'cover_y': 1500,
'id': '26354572',
'is_beetle_subject': False,
'is_new': False,
'playable': True,
'rate': '8.2',
'title': '欢乐好声音',
'url': 'https://movie.douban.com/subject/26354572/'},
{'cover': 'https://img3.doubanio.com/view/movie_poster_cover/lpst/public/p1280323646.jpg',
'cover_x': 1005,
'cover_y': 1437,
'id': '1299398',
'is_beetle_subject': False,
'is_new': False,
'playable': False,
'rate': '8.9',
'title': '大话西游之月光宝盒',
'url': 'https://movie.douban.com/subject/1299398/'}
]}
如上所示,返回结果(json)中的'subjects'字段是一个影片信息列表,一共有20项,每一项都是一部影片的信息,其中可以找到影片片名(title)、评分(rate)以及影片页面url等信息。
连续单击加载按钮,捕获更多jQuery发送的HTTP请求,可以总结出其url的规律:
● type参数:类型,movie代表电影。
● tag参数:分类标签,当前为“豆瓣高分”。
● page_start:从第几部影片开始加载,即结果列表中第一部影片在服务器端的序号。
● page_limit:期望获取的影片信息的数量,当前为20。
我们可以通过分析出的API,每次获取固定数量的影片信息,从中提取每一个影片页面的url,例如:
先获取20部影片信息:
[BASE_URL]?type=movie&tag=豆瓣高分&sort=recommend&page_limit=20&page_start=0
再获取20部影片信息:
[BASE_URL]?type=movie&tag=豆瓣高分&sort=recommend&page_limit=20&page_start=20
再获取20部影片信息:
[BASE_URL]?type=movie&tag=豆瓣高分&sort=recommend&page_limit=20&page_start=40
…
直到返回结果中的影片信息列表为空,说明没有影片了。
接下来分析影片页面。在scrapy shell中下载任意一个影片页面,并调用view函数在浏览器中查看页面,如图13-7所示。
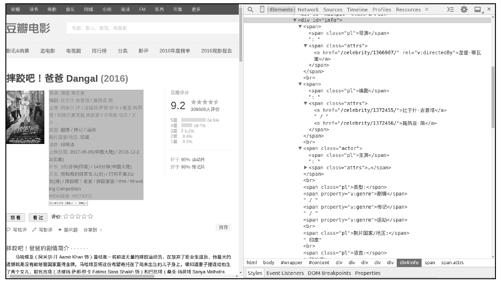
图13-7
从图13-7中可以看出,影片的信息在<div id="info">中,其中每一个信息字段名("导演","编剧"等)都位于一个<span class="pl">中,比较容易提取,但字段的值很难找到统一的规律,我们可以使用XPath的string函数将<div id="info">中的所有文本提取到一个字符串,然后用提取到的字段名分割该字符串,得到其中值的部分。
首先提取包含所有信息的字符串:
>>> info = response.css('div#info').xpath('string(.)').extract_first()
>>> print(info)
导演:涅提·蒂瓦里
编剧:比于什·古普塔 / 施热亚·简
主演:阿米尔·汗 / 法缇玛·萨那·纱卡 / 桑亚·玛荷塔 / 阿帕尔夏克提·库拉那 / 沙克希·坦
沃
/ 泽伊拉·沃西姆 / 苏哈妮·巴特纳格尔 / 里特维克·萨霍里 / 吉里什·库卡尼
类型:剧情 / 传记 / 运动
制片国家/地区:印度
语言:印地语
上映日期:2017-05-05(中国大陆) / 2016-12-23(印度)
片长:161分钟(印度) / 140 分钟(中国大陆)
又名:我和我的冠军女儿(台) / 打死不离3 父女(港) / 摔跤吧!老爸 / 摔跤家族 / ???? /
Wrestling Competition
IMDb链接: tt5074352
再提取所有字段名到一个列表:
>>> fields = [s.strip().replace(':', '') for s in \
... response.css('div#info span.pl::text').extract()]
>>> fields
['导演','编剧','主演','类型','制片国家/地区','语言','上映日期','片长','又名','IMDb 链接']
使用字段名对info进行分割,得到所有值的列表:
>>> import re
>>> values = [re.sub('\s+', ' ', s.strip()) for s in \
... re.split('\s*(?:%s):\s*' % '|'.join(fields), info)][1:]
>>> values
['涅提·蒂瓦里',
'比于什·古普塔 / 施热亚·简',
'阿米尔·汗 / 法缇玛·萨那·纱卡 / 桑亚·玛荷塔 / 阿帕尔夏克提·库拉那 / 沙克希·坦沃 /
泽伊拉·沃西姆 / 苏哈妮·巴特纳格尔 / 里特维克·萨霍里 / 吉里什·库卡尼',
'剧情 / 传记 / 运动',
'印度',
'印地语',
'2017-05-05(中国大陆) / 2016-12-23(印度)',
'161 分钟(印度) / 140 分钟(中国大陆)',
'我和我的冠军女儿(台) / 打死不离3 父女(港) / 摔跤吧!老爸 / 摔跤家族 / ???? /
Wrestling Competition',
'tt5074352']
最后,使用以上两个列表构造影片信息字典:
>>> dict(zip(fields, values))
{'IMDb链接': 'tt5074352',
'上映日期': '2017-05-05(中国大陆) / 2016-12-23(印度)',
'主演':'阿米尔·汗 / 法缇玛·萨那·纱卡 / 桑亚·玛荷塔 / 阿帕尔夏克提·库拉那 / 沙克
希·坦沃 /
泽伊拉·沃西姆 / 苏哈妮·巴特纳格尔 / 里特维克·萨霍里 / 吉里什·库卡尼',
'制片国家/地区': '印度',
'又名':'我和我的冠军女儿(台) / 打死不离3 父女(港) / 摔跤吧!老爸 / 摔跤家族 / ???? /
Wrestling Competition',
'导演':'涅提·蒂瓦里',
'片长': '161 分钟(印度) / 140 分钟(中国大陆)',
'类型':'剧情 / 传记 / 运动',
'编剧': '比于什·古普塔 / 施热亚·简',
'语言':'印地语'}
经上述操作,我们得到了除片名和评分之外的所有信息,片名和评分信息可以在json串中获取。
到此,页面分析的工作完成了。
13.5.3 编码实现
创建Scrapy项目,取名为douban_movie:
$ scrapy startproject douban_movie
在页面分析中,我们详细阐述了爬取过程,现在可以轻松实现MoviesSpider了,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
import re
from pprint import pprint
class MoviesSpider(scrapy.Spider):
BASE_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%s&sort=
recommend&page_limit=%s&page_start=%s'
MOVIE_TAG = '豆瓣高分'
PAGE_LIMIT = 20
page_start = 0
name = "movies"
start_urls = [BASE_URL % (MOVIE_TAG, PAGE_LIMIT, page_start)]
def parse(self, response):
# 使用json 模块解析响应结果
infos = json.loads(response.body.decode('utf-8'))
# 迭代影片信息列表
for movie_info in infos['subjects']:
movie_item = {}
# 提取"片名"和"评分", 填入item.
movie_item['片名'] = movie_info['title']
movie_item['评分'] = movie_info['rate']
# 提取影片页面url,构造Request 发送请求,并将item通过meta 参数传递给影片
页面解析函数
yield Request(movie_info['url'], callback=self.parse_movie,
meta={'_movie_item': movie_item})
# 如果json 结果中包含的影片数量小于请求数量,说明没有影片了,否则继续搜索
if len(infos['subjects']) == self.PAGE_LIMIT:
self.page_start += self.PAGE_LIMIT
url = self.BASE_URL % (self.MOVIE_TAG, self.PAGE_LIMIT, self.page_start)
yield Request(url)
def parse_movie(self, response):
# 从meta 中提取已包含"片名"和"评分"信息的item
movie_item = response.meta['_movie_item']
# 获取整个信息字符串
info = response.css('div.subject div#info').xpath('string(.)').extract_first()
# 提取所有字段名
fields= [s.strip().replace(':', '') for s in \
response.css('div#info span.pl::text').extract()]
# 提取所有字段的值
values = [re.sub('\s+', ' ', s.strip()) for s in \
re.split('\s*(?:%s):\s*' % '|'.join(fields), info)][1:]
# 将所有信息填入item
movie_item.update(dict(zip(fields, values)))
yield movie_item
为了使用代理进行爬取,我们将之前实现的RandomHttpProxyMiddleware复制到该项目中。
在配置文件settings.py中添加如下配置:
# 我们的爬取不符合豆瓣爬取规则,强制爬取
ROBOTSTXT_OBEY = False
# 伪装成常规浏览器
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) Chrome/42.0.2311.90 Safari/537.36'
# 可选。设置下载延迟,防止代理被封禁IP,依据代理数量而定
DOWNLOAD_DELAY = 0.5
# 启用随机代理中间件
DOWNLOADER_MIDDLEWARES = {
'douban_movie.middlewares.RandomHttpProxyMiddleware': 745,
}
# 指定所要使用的代理服务器列表文件
HTTPPROXY_PROXY_LIST_FILE = 'proxy_list.json'
为了爬取稳定,使用在云服务器上自行搭建的代理服务器,手工编辑代理服务器列表文件proxy_list.json:
[
{"proxy_scheme": "https", "proxy": "http://116.29.35.201:8118"},
{"proxy_scheme": "https", "proxy": "http://197.10.171.143:8118"},
{"proxy_scheme": "https", "proxy": "http://112.78.43.67:8118"},
{"proxy_scheme": "https", "proxy": "http://124.59.42.145:8118"}
]
最后,运行爬虫,将结果保存到文件moveis.json:
$ scrapy crawl movies -o movies.json
在Python中观察爬取结果,代码如下:
>>> import json
>>> movies = json.load(open('movies.json'))
>>> for movie in movies:
... print(movie['片名'], movie['评分'], movie['导演'])
...
忠犬八公的故事 9.2 拉斯·霍尔斯道姆
楚门的世界 9.0 彼得·威尔
怦然心动 8.9 罗伯·莱纳
泰坦尼克号 9.2 詹姆斯·卡梅隆
血战钢锯岭 8.7 梅尔·吉布森
驴得水 8.3 周申 / 刘露
星际穿越 9.1 克里斯托弗·诺兰
盗梦空间 9.2 克里斯托弗·诺兰
阿甘正传 9.4 罗伯特·泽米吉斯
千与千寻 9.2 宫崎骏
三傻大闹宝莱坞 9.1 拉吉库马尔·希拉尼
霸王别姬 9.5 陈凯歌
你的名字 8.5 新海诚
金刚狼3:殊死一战 8.3 詹姆斯·曼高德
疯狂动物城 9.2 拜伦·霍华德 / 瑞奇·摩尔 / 杰拉德·布什
爱乐之城 8.3 达米恩·查泽雷
大话西游之月光宝盒 8.9 刘镇伟
触不可及 9.1 奥利维·那卡什 / 艾力克·托兰达
无间道 9.0 刘伟强 / 麦兆辉
让子弹飞 8.7 姜文
...省略中间部分...
哈尔的移动城堡 8.8 宫崎骏
阿凡达 8.6 詹姆斯·卡梅隆
教父 9.2 弗朗西斯·福特·科波拉
罗马假日 8.9 威廉·惠勒
龙猫 9.1 宫崎骏
火星救援 8.4 雷德利·斯科特
超能陆战队 8.6 唐·霍尔 / 克里斯·威廉姆斯
欢乐好声音 8.2 加斯·詹宁斯 / 克里斯托夫·卢尔德莱
少年派的奇幻漂流 9.0 李安
釜山行 8.2 延尚昊
大话西游之大圣娶亲 9.2 刘镇伟
这个杀手不太冷 9.4 吕克·贝松
海上钢琴师 9.2 朱塞佩·托纳多雷
宣告黎明的露之歌 8.1 汤浅政明
肖申克的救赎 9.6 弗兰克·德拉邦特
摔跤吧!爸爸 9.2 涅提·蒂瓦里
>>> len(movies)
500
如上所示,我们成功爬取了“豆瓣高分”分类下的500部影片信息。
13.6 本章小结
本章学习了Scrapy爬虫如何使用代理进行爬取,首先介绍了两种设置代理的方法:
● 使用下载中间件HttpProxyMiddleware(自动)。
● 在构造Request对象时通过meta参数设置(手动)。
前者使用简单,只需通过环境变量配置即可;后者可在某些特殊场景下使用。我们以如何使用多个代理进行了举例,随后讲解了在网络上获取免费代理的方法,并利用获取的免费代理实现了一个随机代理中间件。最后,运用本章所学的知识完成一个实战项目,使用代理爬取了豆瓣网中的电影信息。










