预计阅读本页时间:-

第1章
初识Scrapy
本章首先介绍爬虫的基本概念、工作流程,然后介绍Scrapy的安装和网络爬虫项目的实现流程,使读者对网络爬虫有一个大致的了解,并且建立起网络爬虫的编写思路。本章重点讲解以下内容:
● 网络爬虫及爬虫的工作流程。
● Scrapy的介绍与安装。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
● 网络爬虫编写步骤。
1.1 网络爬虫是什么
网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据。举一个简单的例子,假设你在本地新开了一家以外卖生意为主的餐馆,现在要给菜品定价,此时便可以开发一个爬虫程序,在美团、饿了么、百度外卖这些外卖网站爬取大量其他餐馆的菜品价格作为参考,以指导定价。
一个网络爬虫程序的基本执行流程可以总结为以下循环:
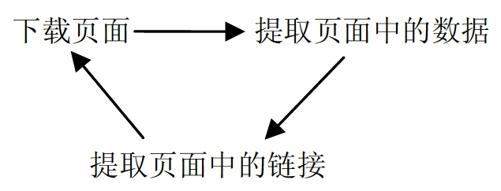
1.下载页面
一个网页的内容本质上就是一个HTML文本,爬取一个网页内容之前,首先要根据网页的URL下载网页。
2.提取页面中的数据
当一个网页(HTML)下载完成后,对页面中的内容进行分析,并提取出我们感兴趣的数据,提取到的数据可以以多种形式保存起来,比如将数据以某种格式(CSV、JSON)写入文件中,或存储到数据库(MySQL、MongoDB)中。
3.提取页面中的链接
通常,我们想要获取的数据并不只在一个页面中,而是分布在多个页面中,这些页面彼此联系,一个页面中可能包含一个或多个到其他页面的链接,提取完当前页面中的数据后,还要把页面中的某些链接也提取出来,然后对链接页面进行爬取(循环1-3步骤)。
设计爬虫程序时,还要考虑防止重复爬取相同页面(URL去重)、网页搜索策略(深度优先或广度优先等)、爬虫访问边界限定等一系列问题。
从头开发一个爬虫程序是一项烦琐的工作,为了避免因制造轮子而消耗大量时间,在实际应用中我们可以选择使用一些优秀的爬虫框架,使用框架可以降低开发成本,提高程序质量,让我们能够专注于业务逻辑(爬取有价值的数据)。接下来,本书就带你学习目前非常流行的开源爬虫框架Scrapy。
1.2 Scrapy简介及安装
Scrapy是一个使用Python语言(基于Twisted框架)编写的开源网络爬虫框架,目前由Scrapinghub Ltd维护。Scrapy简单易用、灵活易拓展、开发社区活跃,并且是跨平台的。在Linux、 MaxOS以及Windows平台都可以使用。Scrapy应用程序也使用Python进行开发,目前可以支持Python 2.7以及Python 3.4+版本。
在任意操作系统下,可以使用pip安装Scrapy,例如:
$ pip install scrapy
为确认Scrapy已安装成功,首先在Python中测试能否导入Scrapy模块:
>>> import scrapy
>>> scrapy.version_info
(1, 3, 3)
然后,在shell中测试能否执行Scrapy这条命令:
$ scrapy
Scrapy 1.3.3 - no active project
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
通过了以上两项检测,说明Scrapy安装成功了。如上所示,我们安装的是当前最新版本1.3.3。
1.3 编写第一个Scrapy爬虫
为了帮助大家建立对Scrapy框架的初步印象,我们使用它完成一个简单的爬虫项目。
1.3.1 项目需求
在专门供爬虫初学者训练爬虫技术的网站(http://books.toscrape.com)上爬取书籍信息,如图1-1所示。
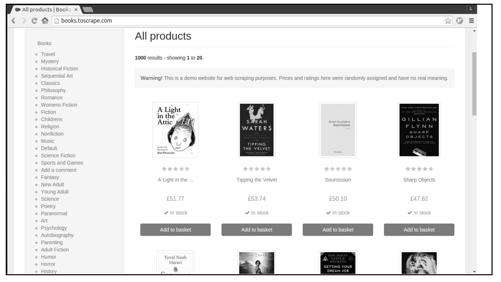
图1-1
该网站中,这样的书籍列表页面一共有50页,每页有20本书,第一个例子应尽量简单。我们下面仅爬取所有图书(1000本)的书名和价格信息。
1.3.2 创建项目
首先,我们要创建一个Scrapy项目,在shell中使用scrapy startproject命令:
$ scrapy startproject example
New Scrapy project 'example', using template directory
'/usr/local/lib/python3.4/dist-packages/scrapy/templates/project', created in:
/home/liushuo/book/example
You can start your first spider with:
cd example
scrapy genspider example example.com
创建好一个名为example的项目后,可使用tree命令查看项目目录下的文件,显示如下:

随着后面逐步深入学习,大家会了解这些文件的用途,此处不做解释。
1.3.3 分析页面
编写爬虫程序之前,首先需要对待爬取的页面进行分析,主流的浏览器中都带有分析页面的工具或插件,这里我们选用Chrome浏览器的开发者工具(Tools→Developer tools)分析页面。
1.数据信息
在Chrome浏览器中打开页面http://books.toscrape.com,选中其中任意一本书并右击,然后选择“审查元素”,查看其HTML代码,如图1-2所示。
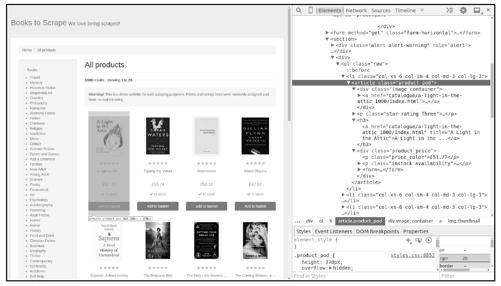
图1-2
可以看到,每一本书的信息包裹在<article class="product_pod">元素中:书名信息在其下h3 > a元素的title属性中,如<a href="catalogue/a-light-in-the-attic_1000/index.html"title="A Light in the Attic">A Light in the...</a>;书价信息在其下<p class="price_color">元素的文本中,如<p class="price_color">£51.77</p>。
2.链接信息
图1-3所示为第一页书籍列表页面,可以通过单击next按钮访问下一页,选中页面下方的next按钮并右击,然后选择“审查元素”,查看其HTML代码,如图1-3所示。
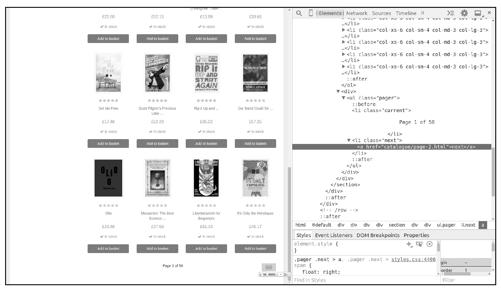
图1-3
可以发现,下一页的URL在ul.pager > li.next > a元素的href属性中,是一个相对URL地址,如<li class="next"><a href="catalogue/page-2.html">next</a></li>。
1.3.4 实现Spider
分析完页面后,接下来编写爬虫。在Scrapy中编写一个爬虫,即实现一个scrapy.Spider的子类。
实现爬虫的Python文件应位于exmaple/spiders目录下,在该目录下创建新文件book_spider.py。然后,在book_spider.py中实现爬虫BooksSpider,代码如下:
# -*- coding: utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
# 每一个爬虫的唯一标识
name = "books"
# 定义爬虫爬取的起始点,起始点可以是多个,这里只有一个
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
# 提取数据
# 每一本书的信息在<article class="product_pod">中,我们使用
# css()方法找到所有这样的article 元素,并依次迭代
for book in response.css('article.product_pod'):
# 书名信息在article > h3 > a 元素的title属性里
# 例如: <a title="A Light in the Attic">A Light in the ...</a>
name = book.xpath('./h3/a/@title').extract_first()
# 书价信息在 <p class="price_color">的TEXT中。
# 例如: <p class="price_color">£51.77</p>
price = book.css('p.price_color::text').extract_first()
yield {
'name': name,
'price': price,
}
# 提取链接
# 下一页的url 在ul.pager > li.next > a 里面
# 例如: <li class="next"><a href="catalogue/page-2.html">next</a></li>
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
# 如果找到下一页的URL,得到绝对路径,构造新的Request 对象
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
如果上述代码中有看不懂的部分,大家不必担心,更多详细内容会在后面章节学习,这里只要先对实现一个爬虫有个整体印象即可。
下面对BooksSpider的实现做简单说明。
● name属性
一个Scrapy项目中可能有多个爬虫,每个爬虫的name属性是其自身的唯一标识,在一个项目中不能有同名的爬虫,本例中的爬虫取名为'books'。
● start_urls属性
一个爬虫总要从某个(或某些)页面开始爬取,我们称这样的页面为起始爬取点,start_urls属性用来设置一个爬虫的起始爬取点。在本例中只有一个起始爬取点'http://books.toscrape.com'。
● parse方法
当一个页面下载完成后,Scrapy引擎会回调一个我们指定的页面解析函数(默认为parse方法)解析页面。一个页面解析函数通常需要完成以下两个任务:
 提取页面中的数据(使用XPath或CSS选择器)。
提取页面中的数据(使用XPath或CSS选择器)。
提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常被实现成一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句提交给Scrapy引擎。
1.3.5 运行爬虫
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl <SPIDER_NAME>命令运行爬虫'books',并将爬取的数据存储到csv文件中:
$ scrapy crawl books -o books.csv
2016-12-27 15:19:53 [scrapy] INFO: Scrapy 1.3.3 started (bot: example)
2016-12-27 15:19:53 [scrapy] INFO: INFO: Overridden settings: {'BOT_NAME': 'example',
'SPIDER_MODULES': ['example.spiders'], 'ROBOTSTXT_OBEY': True, 'NEWSPIDER_MODULE':
'example.spiders'}
2016-12-27 15:19:53 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2016-12-27 15:19:53 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-12-27 15:19:53 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-12-27 15:19:53 [scrapy] INFO: Enabled item pipelines:
[]
2016-12-27 15:19:53 [scrapy] INFO: Spider opened
2016-12-27 15:19:53 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0
items/min)
2016-12-27 15:19:53 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-12-27 15:20:01 [scrapy] DEBUG: Crawled (404) (referer: None)
2016-12-27 15:20:02 [scrapy] DEBUG: Crawled (200) (referer: None)
2016-12-27 15:20:02 [scrapy] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'A Light in the Attic', 'price': '£51.77'}
2016-12-27 15:20:02 [scrapy] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Tipping the Velvet', 'price': '£53.74'}
2016-12-27 15:20:02 [scrapy] DEBUG: Scraped from <200 http://books.toscrape.com/>
{'name': 'Soumission', 'price': '£50.10'}
... <省略中间部分输出> ...
2016-12-27 15:21:30 [scrapy] DEBUG: Scraped from <200
http://books.toscrape.com/catalogue/page-50.html>
{'name': '1,000 Places to See Before You Die', 'price': '£26.08'}
2016-12-27 15:21:30 [scrapy] INFO: Closing spider (finished)
2016-12-27 15:21:30 [scrapy] INFO: Stored csv feed (1000 items) in: books.csv
2016-12-27 15:21:30 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 14957,
'downloader/request_count': 51,
'downloader/request_method_count/GET': 51,
'downloader/response_bytes': 299924,
'downloader/response_count': 51,
'downloader/response_status_count/200': 50,
'downloader/response_status_count/404': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 12, 27, 7, 21, 30, 10396),
'item_scraped_count': 1000,
'log_count/DEBUG': 1052,
'log_count/INFO': 9,
'request_depth_max': 49,
'response_received_count': 51,
'scheduler/dequeued': 50,
'scheduler/dequeued/memory': 50,
'scheduler/enqueued': 50,
'scheduler/enqueued/memory': 50,
'start_time': datetime.datetime(2016, 12, 27, 7, 19, 53, 194334)}
2016-12-27 15:21:30 [scrapy] INFO: Spider closed (finished)
等待爬虫运行结束后,在books.csv文件中查看爬取到的数据,代码如下:
$ sed -n '2,$p' books.csv | cat -n # 不显示第一行的csv 头部
1 A Light in the Attic,£51.77
2 Tipping the Velvet,£53.74
3 Soumission,£50.10
4 Sharp Objects,£47.82
5 Sapiens: A Brief History of Humankind,£54.23
6 The Requiem Red,£22.65
7 The Dirty Little Secrets of Getting Your Dream Job,£33.34
... <省略中间部分输出> ...
995 Beyond Good and Evil,£43.38
996 Alice in Wonderland (Alice's Adventures in Wonderland #1),£55.53
997 "Ajin: Demi-Human, Volume 1 (Ajin: Demi-Human #1)",£57.06
998 A Spy's Devotion (The Regency Spies of London #1),£16.97
999 1st to Die (Women's Murder Club #1),£53.98
1000 "1,000 Places to See Before You Die",£26.08
从上述数据可以看出,我们成功地爬取到了1000本书的书名和价格信息(50页,每页20项)。
1.4 本章小结
本章是开始Scrapy爬虫之旅的第1章,先带大家了解了什么是网络爬虫,然后对Scrapy爬虫框架做了简单介绍,最后以一个简单的爬虫项目让大家对开发Scrapy爬虫有了初步的印象。在接下来的章节中,我们将深入学习开发Scrapy爬虫的核心基础内容。










