预计阅读本页时间:-

第三节 基于盈余时间序列的简化预测
上一节中介绍的结构化盈余预测充分利用过去的会计信息,并充分考虑未来重大经济、行业、公司事件对盈余发展的影响。相比较而言,基于盈余时间序列的简化预测具有使用的信息量少、预测过程简便的特点。同时,简化预测还有一个重要的优点:它通过统计方法可以发现预测者不容易直观看到的盈余时间序列的统计特征,并把这种特征使用到盈余预测当中去。
所谓基于盈余时间序列的简化预测,是指在盈余(以年度盈余为例)历史序列的基础上,通过统计方法发现某年的盈余和其上一年盈余之间的相关关系,然后根据这一相关关系,预测下一年的盈余水平。
具体来说,如果我们的目标是预测某公司2008年的盈余,而我们手中有该公司1991年到2007年的盈余数据。这样,我们可以做下面的回归分析:
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
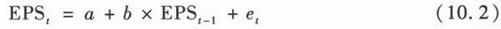
EPS是指某公司t年的每股净盈余,该公司年的每股净盈余,a和b是回归模型的常数项和回归系数,e是随机扰动项。我们将1991—2006年每股净盈余的历史数据代入到公式(10.2)做线性回归的含义是发掘该公司某年的盈余和其上一年盈余之间的相关关系,得到的回归结果是对a和b的估计。例如,如果我们估计的结果是a等于0和b等于1,也就意味着对于该公司的盈余来讲,对下一期每股净盈余的预测应该是本期每股净盈余(即下期盈余=0+1×本期盈余),本期是多少就预测下期是多少。以此类推,对未来各期的最好预测都是本期的每股净盈余。
如果某公司的每股净盈余符合这样的统计规律,我们称该公司的盈余遵守随机游走过程。虽然每股净盈余完全符合随机游走过程的公司很少见,但并不是没有的。一个典型的例子是一个完全从事股票投资并采用公允价值计量的基金公司,因为股票价格变化基本遵守随机游走模型,该基金公司的盈余也大体如此。
在实际使用公式(10.2)进行回归估计过程中,我们不能够使用每股净盈余的水平,而是要把每股净盈余除以期初每股权益、每股资产或每股股票价格。
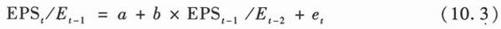
Et-1代表t-1期每股股东权益(或每股资产,或每股股票价格),Et-2的定义类似。每股净盈余除以每股权益等变量的这个过程叫做标准化。之所以在回归过程中把每股净盈余标准化,是因为每股净盈余在企业之间是不具有可比性的。两个盈利能力和价值完全相同的企业,每年净盈余都是一样的,但是一个企业发行的普通股股票数目是另一个企业的两倍,其每股净盈余自然只有另一个企业的一半。所以,通过每股净盈余水平的高低来判断企业的盈利能力差别是不对的。回归分析实际上是在不同的观察值之间做比较,因为每股净盈余不能作为比较对象,所以我们在回归时必须把它标准化。标准化后的变量(实际上是回报率)是可以在企业之间比较的,也是可以用来做回归分析的。
同样的问题和道理也适用于同一个企业的每股净盈余时间序列。因为企业的资本结构不断处于变化当中,企业的股票数目或者每股所代表的权益都在企业历史上发生了变化,因此,即使就同一个企业的历史数据来回归,也应该先对每股净盈余标准化,否则,回归所使用的历史数据的可比性是有问题的,得到的回归估计结果也不准确。
让我们回到公式(10.3),对于某一个公司来讲,我们将其标准化后的盈余历史数据根据公式(10.3)进行回归,得到对a和b的估计值后,将本期的每股净盈余除以本期期初每股权益,然后再乘以本期期末(下期期初)每股权益,就得到对下期每股净盈余的预测。以后期间的盈余预测以此类推。
读者肯定已经意识到,公式(10.3)中的变量就是股东权益回报率或资产回报率。我们对盈余水平的预测实际上是建立在对企业盈利能力预测的基础上。
我们在第八章中讨论了盈利能力的均值回转特征,当企业本期盈余水平过高时,以后往往倾向于下滑;当本期盈余水平过低时,以后往往倾向于上升。盈利能力的均值回转特征通过公式(10.3)的估计同样可以表现出来。首先,我们把所有有历史数据的上市公司分别做公式(10.3)的回归估计,得出每一个公司的a和b的估计值,然后在所有公司间取平均数。b的估计值的平均数基本会是一个在0到1之间的数值,也即表明企业的盈余遵循均值回转特征。
Sloan(1996)根据美国上市公司1962—1991年的历史数据对公式(10.3)进行了估计,得到的a和b的平均估计值是0.015和0.841。所以,如果我们要预测1993年一个典型美国上市公司的每股净盈余,可以把这个公司1992年的标准化每股净盈余数据代入公式(10.3),就得到了对其1993年每股净盈余的预测。
到这里,我们可以感觉到简化预测方法相对于结构化预测方法的一个特点。简化预测方法因其可以通过统计手段迅速利用大样本的数据进行统计分析,发现盈余数据间的统计规律并加以利用。这是结构化预测方法做不到的。在实际预测工作中,结构化预测方法因其对会计历史信息利用充分,并可以更好地融合非会计信息对未来盈余的影响,应该是我们进行盈余预测的主要方法。但是简化预测方法的优势也表明,我们应该两者并用,尤其是通过简化、统计预测方法发掘历史数据中的普遍规律(如均值回转特征),然后把这些特征结合到结构化盈余预测中去,从而提高结构化盈余预测的准确性。同时,两种方法的预测结果可以相互印证。
当然,在某些情况下,完整的历史会计报表可能得不到,或者预测任务比较紧迫,这时简化预测方法就成为首选的预测方法。
公式(10.3)是简单地利用盈余的时间序列来进行预测。为了提高预测准确性,我们还可以对公式(10.3)进行扩展,主要是将每股净盈余进行分解。将每股净盈余分解成其组成部分能够提高预测准确性是因为在公式(10.3)中,我们实际上是假设各个盈余组成部分对企业未来盈余的贡献是一样的。事实上;不同的盈余组成部分对未来盈余的贡献是不同的。通过分解后再回归,我们对不同部分区别对待,能够充分利用各个组成部分中包含的预测信息。
一个最简单的分解是将每股净盈余分解为每股现金盈余和应计盈余。[6]Sloan(1996)发现这两部分盈余的持续性不同,因此对未来盈余的影响也有差别。公式(10.3)不区分这两者的差别,实际上忽略了这种差别对预测的影响。因此,我们可以把公式(10.3)扩展为:
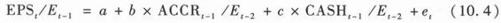
公式(10.4)中ACCR代表每股应计盈余,CASH代表每股现金盈余。其他变量的定义和公式(10.3)中相同。
Sloan(1996)根据美国上市公司1962—1991年的历史数据估计了公式(10.4),结果a是0.011,b是0.765,c是0.855。同样,我们把1992年的数据代入公式,就可以得到对一个典型上市公司1993年每股净盈余的预测,并且公式(10.4)的预测比公式(10.3)的预测更加准确。
李远鹏、牛建军(2007)[7]使用我国上市公司1998—2002年的数据,对公式(10.4)进行了估计,结果得到a是0.000,b是0.520,c是0.646。同样,我们可以用这些系数的估计值,把2003年的典型上市公司数据代入公式(10.4),预测其2004年的每股净盈余。
将净盈余分解成应计盈余和现金盈余来预测未来盈余只是分解盈余的方法之一,预测者可以采用不同的标准分解盈余,以达到提高预测准确性的目的。例如,根据损益表的结构,我们可以把净盈余分解成经营性盈余、非经营性盈余等部分,或者分解成收入和各个成本费用项目,甚至在分解盈余的同时在预测模型中加入损益表以外的信息。这里本书就不做更细的介绍。总之,回归模型中使用的信息量越大,模型预测的准确性也就越高。










