预计阅读本页时间:-

第8章
项目练习
通过之前章节的学习,大家掌握了编写Scrapy爬虫的基础知识,这一章我们运用之前所学进行实战项目练习。
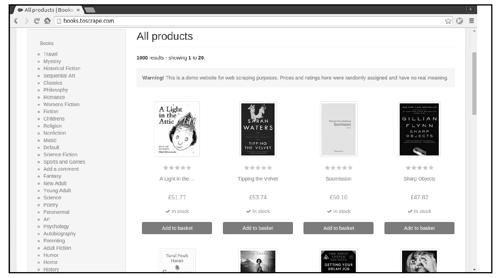
在第1章的example项目中,我们爬取了http://books.toscrape.com网站中的书籍信息,但仅从每一个书籍列表页面爬取了书的名字和价格信息,如图8-1所示。
通常,实际应用需求并不会这么简单,可能需要获取每本书的更多信息,在具体一本书的页面中可以找到更多的信息,点击第一本书的链接,将看到如图8-2所示的页面。
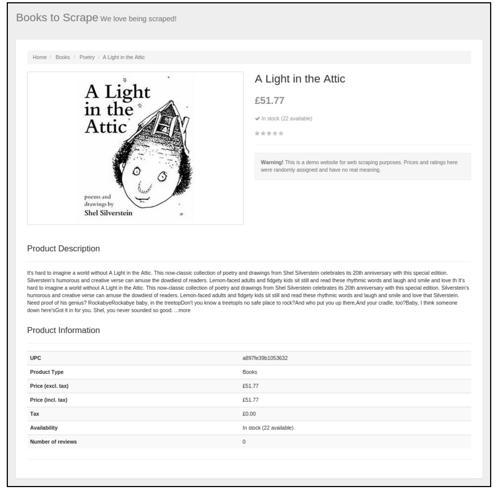
图8-2
如上所示,在一本书的页面中可以获取以下信息:
● 书名√
● 价格√
● 评价等级√
● 书籍简介
● 产品编码√
● 产品类型
● 税价
● 库存量√
● 评价数量√
下面我们新建一个Scrapy项目,爬取每一本书更多的信息(只爬取其中打对号的信息)。
8.1 项目需求
下面爬取http://books.toscrape.com网站中的书籍信息。
(1)其中每一本书的信息包括:
 书名
书名
价格
评价等级
产品编码
库存量
评价数量
(2)将爬取的结果保存到csv文件中。
8.2 页面分析
首先,我们对一本书的页面进行分析。在进行页面分析时,除了之前使用过的Chrome开发者工具外,另一个常用的工具是scrapy shell <URL>命令,它使用户可以在交互式命令行下操作一个Scrapy爬虫,通常我们利用该工具进行前期爬取实验,从而提高开发效率。
接下来分析第一本书的页面,以页面的url地址为参数运行scrapy shell命令:
$ scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
2017-03-03 09:17:01 [scrapy] INFO: Scrapy 1.3.3 started (bot: scrapybot)
2017-03-03 09:17:01 [scrapy] INFO: Overridden settings: {'LOGSTATS_INTERVAL': 0,
'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter'}
2017-03-03 09:17:01 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2017-03-03 09:17:01 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-03-03 09:17:01 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-03-03 09:17:01 [scrapy] INFO: Enabled item pipelines:
[]
2017-03-03 09:17:01 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2017-03-03 09:17:01 [scrapy] INFO: Spider opened
2017-03-03 09:17:01 [scrapy] DEBUG: Crawled (200) (referer: None)
2017-03-03 09:17:02 [traitlets] DEBUG: Using default logger
2017-03-03 09:17:02 [traitlets] DEBUG: Using default logger
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>>
运行这条命令后,scrapy shell会使用url参数构造一个Request对象,并提交给Scrapy引擎,页面下载完成后,程序进入一个python shell当中,在此环境中已经创建好了一些变量(对象和函数),以下几个最为常用:
● request
最近一次下载对应的Request对象。
● response
最近一次下载对应的Response对象。
● fetch(req_or_url)
该函数用于下载页面,可传入一个Request对象或url字符串,调用后会更新变量request和response。
● view(response)
该函数用于在浏览器中显示response中的页面。
接下来,在scrapy shell中调用view函数,在浏览器中显示response所包含的页面:
>>> view(response)
可能在很多时候,使用view函数打开的页面和在浏览器直接输入url打开的页面看起来是一样的,但需要知道的是,前者是由Scrapy爬虫下载的页面,而后者是由浏览器下载的页面,有时它们是不同的。在进行页面分析时,使用view函数更加可靠。下面使用Chrome审查元素工具分析页面,如图8-3所示。
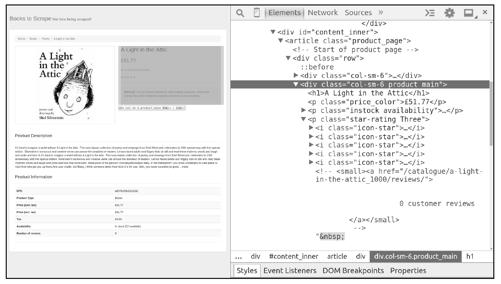
图8-3
从图8-3中看出,我们可在<div class="col-sm-6 product_main">中提取书名、价格、评价等级,在scrapy shell中尝试提取这些信息,如图8-4所示。
>>> sel = response.css('div.product_main')
>>> sel.xpath('./h1/text()').extract_first()
'A Light in the Attic'
>>> sel.css('p.price_color::text').extract_first()
'£51.77'
>>> sel.css('p.star-rating::attr(class)').re_first('star-rating ([A-Za-z]+)')
'Three'

图8-4
另外,可在页面下端位置的<table class="table table-striped">中提取产品编码、库存量、评价数量,在scrapy shell中尝试提取这些信息:
>>> sel = response.css('table.table.table-striped')
>>> sel.xpath('(.//tr)[1]/td/text()').extract_first()
'a897fe39b1053632'
>>> sel.xpath('(.//tr)[last()-1]/td/text()').re_first('\((\d+) available\)')
'22'
>>> sel.xpath('(.//tr)[last()]/td/text()').extract_first()
'0'
分析完书籍页面后,接着分析如何在书籍列表页面中提取每一个书籍页面的链接。在scrapy shell中,先调用fetch函数下载第一个书籍列表页面(http://books.toscrape.com/),下载完成后再调用view函数在浏览器中查看页面,如图8-5所示。
>>> fetch('http://books.toscrape.com/')
[scrapy] DEBUG: Crawled (200) <GET http://books.toscrape.com/> (referer: None)
>>> view(response)
图8-5
每个书籍页面的链接可以在每个<article class="product_pod">中找到,在scrapy shell中使用LinkExtractor提取这些链接:
>>> from scrapy.linkextractors import LinkExtractor
>>> le = LinkExtractor(restrict_css='article.product_pod')
>>> le.extract_links(response)
[Link(url='http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html', text='',
fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/soumission_998/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/sharp-objects_997/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/the-requiem-red_995/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/i
ndex.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-in
famous-feminist-victoria-woodhull_993/index.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-que
st-for-gold-at-the-1936-berlin-olympics_992/index.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/the-black-maria_991/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.ht
ml', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html', text='',
fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/set-me-free_988/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/i
ndex.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html', text='',
fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american
-indie-underground-1981-1991_985/index.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/olio_984/index.html', text='', fragment='',
nofollow=False),
Link(url='http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_
983/index.html', text='', fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html', text='',
fragment='', nofollow=False),
Link(url='http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html', text='',
fragment='', nofollow=False)]
到此,页面分析的工作已经完成了。
8.3 编码实现
首先创建一个Scrapy项目,取名为toscrape_book。
$ scrapy startproject toscrape_book
通常,我们不需要手工创建Spider文件以及Spider类,可以使用scrapy genspider<SPIDER_NAME> <DOMAIN>命令生成(根据模板)它们,该命令的两个参数分别是Spider的名字和所要爬取的域(网站):
$ cd toscrape_book
$ scrapy genspider books books.toscrape.com
运行后,scrapy genspider命令创建了文件toscrape_book/spiders/books.py,并在其中创建了一个BooksSpider类,代码如下:
# -*- coding: utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
pass
实现Spider之前,先定义封装书籍信息的Item类,在toscrape_book/items.py中添加如下代码:
class BookItem(scrapy.Item):
name = scrapy.Field() # 书名
price = scrapy.Field() # 价格
review_rating = scrapy.Field() # 评价等级,1~5 星
review_num = scrapy.Field() # 评价数量
upc = scrapy.Field() # 产品编码
stock = scrapy.Field() # 库存量
接下来,按以下5步完成BooksSpider。
步骤 01 继承Spider创建BooksSpider类(已完成)。
步骤 02 为Spider取名(已完成)。
步骤 03 指定起始爬取点(已完成)。
步骤 04 实现书籍列表页面的解析函数。
步骤 05 实现书籍页面的解析函数。
其中前3步已经由scrapy genspider命令帮我们完成,不需做任何修改。
第4步和第5步的工作是实现两个页面解析函数,因为起始爬取点是一个书籍列表页面,我们就将parse方法作为书籍列表页面的解析函数,另外,还需要添加一个parse_book方法作为书籍页面的解析函数,代码如下:
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ['http://books.toscrape.com/']
# 书籍列表页面的解析函数
def parse(self, response):
pass
# 书籍页面的解析函数
def parse_book(self, reponse):
pass
先来完成第4步,实现书籍列表页面的解析函数(parse方法),需要完成以下两个任务:
(1)提取页面中每一个书籍页面的链接,用它们构造Request对象并提交。
(2)提取页面中下一个书籍列表页面的链接,用其构造Request对象并提交。
提取链接的具体细节在页面分析时已经讨论过,实现代码如下:
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ['http://books.toscrape.com/']
# 书籍列表页面的解析函数
def parse(self, response):
# 提取书籍列表页面中每本书的链接
le = LinkExtractor(restrict_css='article.product_pod h3')
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback=self.parse_book)
# 提取"下一页"的链接
le = LinkExtractor(restrict_css='ul.pager li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(next_url, callback=self.parse)
# 书籍页面的解析函数
def parse_book(self, response):
pass
最后完成第5步,实现书籍页面的解析函数(parse_book方法),只需提取书籍信息存入BookItem对象即可。同样,提取书籍信息的细节也在页面分析时讨论过,最终完成代码如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import BookItem
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
le = LinkExtractor(restrict_css='article.product_pod h3')
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback=self.parse_book)
le = LinkExtractor(restrict_css='ul.pager li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(next_url, callback=self.parse)
def parse_book(self, response):
book = BookItem()
sel = response.css('div.product_main')
book['name'] = sel.xpath('./h1/text()').extract_first()
book['price'] = sel.css('p.price_color::text').extract_first()
book['review_rating'] = sel.css('p.star-rating::attr(class)')\
.re_first('star-rating ([A-Za-z]+)')
sel = response.css('table.table.table-striped')
book['upc'] = sel.xpath('(.//tr)[1]/td/text()').extract_first()
book['stock'] = sel.xpath('(.//tr)[last()-1]/td/text()')\
.re_first('\((\d+) available\)')
book['review_num'] = sel.xpath('(.//tr)[last()]/td/text()').extract_first()
yield book
完成代码后,运行爬虫并观察结果:
$ scrapy crawl books -o books.csv --nolog
$ cat -n books.csv
1 name,stock,price,review_num,review_rating,upc
2 Scott Pilgrim's Precious Little Life,19,£52.29,0,Five,3b1c02bac2a429e6
3 It's Only the Himalayas,19,£45.17,0,Two,a22124811bfa8350
4 Olio,19,£23.88,0,One,feb7cc7701ecf901
5 Rip it Up and Start Again,19,£35.02,0,Five,a34ba96d4081e6a4
... 省略中间输出 ...
999 Bright Lines,1,£39.07,0,Five,230ac636ea0ea415
1000 Jurassic Park (Jurassic Park #1),3,£44.97,0,One,a0dd11f6abc421ec
1001 Into the Wild,3,£56.70,0,Five,a7c3f1010d64799a
从以上结果中看出,我们成功地爬取了网站中1000本书的详细信息,但也有让人不满意的地方,比如csv文件中各列的次序是随机的,看起来比较混乱,可在配置文件settings.py中使用FEED_EXPORT_FIELDS指定各列的次序:
FEED_EXPORT_FIELDS = ['upc', 'name', 'price', 'stock', 'review_rating', 'review_num']
另外,结果中评价等级字段的值是One、Two、Three……这样的单词,而不是阿拉伯数字,阅读起来不是很直观。下面实现一个Item Pipeline,将评价等级字段由单词映射到数字(或许这样简单的需求使用Item Pipeline有点大材小用,主要目的是带领大家复习之前所学的知识)。在pipelines.py中实现BookPipeline,代码如下:
class BookPipeline(object):
review_rating_map = {
'One': 1,
'Two': 2,
'Three': 3,
'Four': 4,
'Five': 5,
}
def process_item(self, item, spider):
rating = item.get('review_rating')
if rating:
item['review_rating'] = self.review_rating_map[rating]
return item
在配置文件settings.py中启用BookPipeline:
ITEM_PIPELINES = {
'toscrape_book.pipelines.BookPipeline': 300,
}
重新运行爬虫,并观察结果:
$ scrapy crawl books -o books.csv
...
$ cat -n books.csv
1 upc,name,price,stock,review_rating,review_num
2 a897fe39b1053632,A Light in the Attic,£51.77,22,3,0
3 3b1c02bac2a429e6,Scott Pilgrim's Precious Little Life,£52.29,19,5,0
4 a22124811bfa8350,It's Only the Himalayas,£45.17,19,2,0
5 feb7cc7701ecf901,Olio,£23.88,19,1,0
... 省略中间输出 ...
999 91eb9605998a7c03,"The Sandman, Vol. 3: Dream Country",£55.55,3,5,0
1000 f06039c29b5891fa,The Silkworm (Cormoran Strike #2),£23.05,3,5,0
1001 476c7972e9b41891,The Last Painting of Sara de Vos,£55.55,3,2,0
此时,各字段已按指定次序排列,并且评价等级字段的值是我们所期望的阿拉伯数字。
到此为止,整个项目完成了。
8.4 本章小结
本章是基础篇的最后一章,通过一个Scrapy爬虫项目复习了之前章节所学的知识,现在,大家已经能够编写一个一般任务的Scrapy爬虫了,可以通过更多的实战项目进行练习,在后面的章节中,我们将会学习一些高级话题。









