已读40%
预计阅读本页时间:-
预计阅读本页时间:-

分析
二分查找每次执行循环时都会大约将问题折半进行处理。将大小为n的集合折半的最大次数为log(n),如果n是2的幂;否则的话,就是 log(n)」。如果我们仅仅使用一个操作来决定两个元素是相等,小于或者大于(这个决定也许是有Comparable接口来做出的),那么仅仅需要log(n)」次比较操作,这个算法的性能是O(log n)的。
log(n)」。如果我们仅仅使用一个操作来决定两个元素是相等,小于或者大于(这个决定也许是有Comparable接口来做出的),那么仅仅需要log(n)」次比较操作,这个算法的性能是O(log n)的。
我们执行了100次实验,每次实验在集合中执行524 288次查找,这个集合是存储在内存中的,大小为n(n的范围是从4096~524 288),目标存在于这个集合中的概率是p(在1.0、0.5和0.0处采样)。表5-2列出的是在抛弃最好和最坏的实验结果后,剩余98次实验的平均结果。

设计这些实验的目的是确保在p=1.0时,集合中的所有元素都能够等概率地被查找到,如果不是这样的话,那么这个结果将是不可靠的。对于顺序查找和二分查找来说,输入时一个有序的整数数组,整数的范围在[0,n)。为了产生524 288个目标元素,并且这些元素都在这个集合中(p=1),我们循环地产生n个元素524 288/n次。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
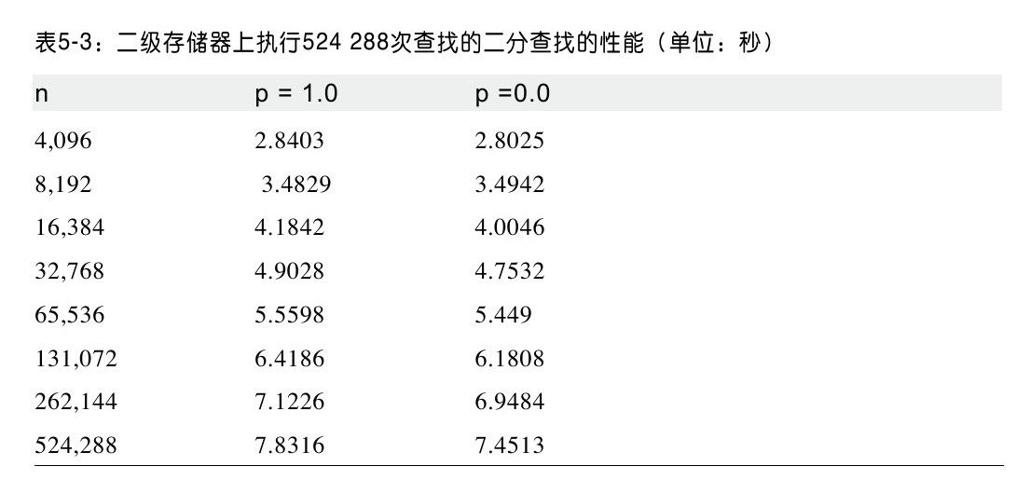
表5-3列出了在本地磁盘上执行524 288次查找的时间。目标元素要么总是存在于集合中(例如p=1.0)或者从不存在(例如,我们在集合[0,n)中查找-1)。数据是一个简单的文件,文件存储的是按升序排列的整数,每个整数是4个字节。磁盘存储的优劣势是非常明显的。因为表5-3的结果相比表5-2的结果要慢近200倍。当n加倍时,你将会注意到查找只是增加了固定的时间,这种特性非常明显地表明了二分查找是O(log n)算法。