预计阅读本页时间:-

使用环境
我们使用如下的八数码:

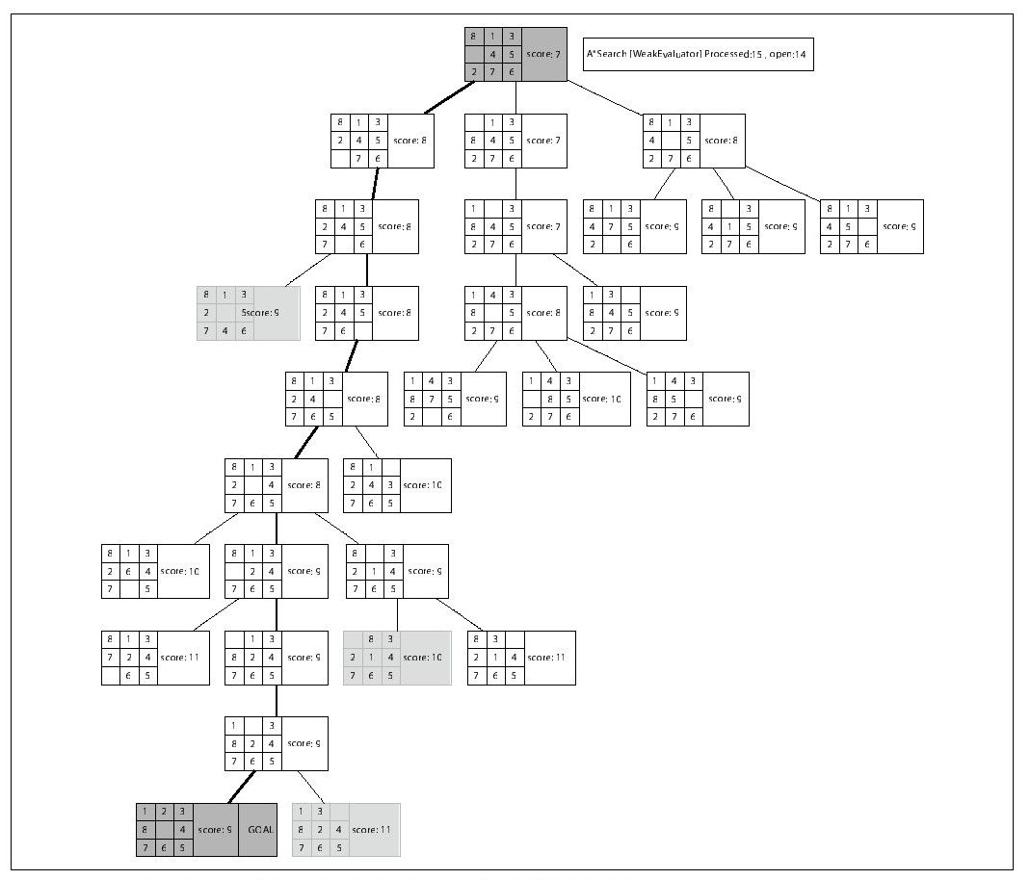
图7-11和图7-12是两棵计算出的搜索树。图7-11的搜索树使用的是Nilsson(1971)提出的GoodEvaluatorf*(n)函数。图7-12的搜索树使用的是同样由Nilsson提出的WeakEvaluator f*(n)函数。浅灰色的棋面状态表示达到目标状态时开放集合的元素。GoodEvaluator和WeakEvaluator都能够得到同样的解,但是使用GoodEvaluator函数在搜索中更加高效。根据两棵树中f*(n)的值,我们希望知道为什么WeakEvaluator需要访问更多的节点。仔细观察在GoodEvaluator产生的搜索树的最初两步,我们可以清楚地看到f*(n)呈递减趋势。而WeakEvaluator的搜索树在走了4步之后才能够减少搜索的候选方向。WeakEvaluator不能很好地差异化棋面状态,事实上,目标状态节点的f*(n)值比初始状态节点以及其子节点的f*(n)都大。
f*(n)函数的h*(n)部分需要非常优秀的设计,这是一门工程而不是一门科学。h*(n)必须非常高效,否则,搜索时间将会非常长。很多A*搜索相关的文献都指出,h*(n)函数是高度特化的,根据问题的不同而不同。例如在数字地形的寻路(Wichmann和Wuensche,2004)或者是有限资源下的工程排期(Hartmann,1999)。Pearl(1984)写过一篇设计高效启发式函数的文章(很遗憾已经绝版了)。Korf(2000)讨论了设计可行h*(n)函数的高级策略。Michalewicz和Fogel(2004)提出了一种新的解决问题的启发式思路,不仅仅是只能用于A*搜索。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元