已读80%
预计阅读本页时间:-
预计阅读本页时间:-

分析
我们随机生成100次二维点集,然后在这些数据基础上进行实验,舍弃最好和最坏的结果,表9-3是剩余98次实验的平均结果。同时对比了使用和不使用启发式函数,性能上存在的差异。
在[0,1]这个单位正方形上,均匀分布着n个点,表9-3的统计结果也许能够给出为什么凸包扫描算法能够如此高效的深层次原因。
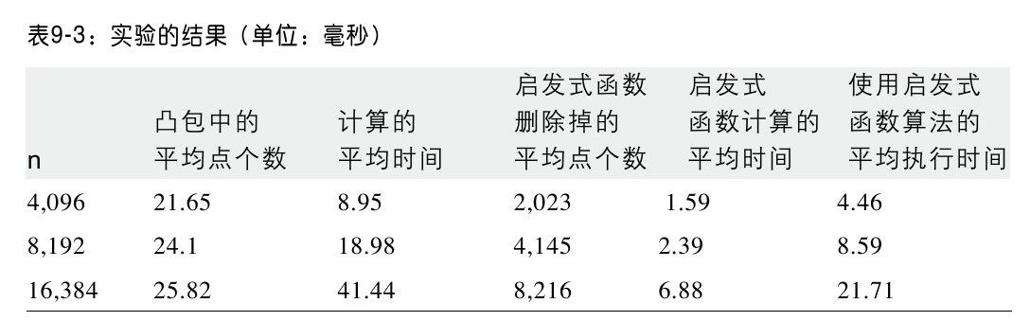
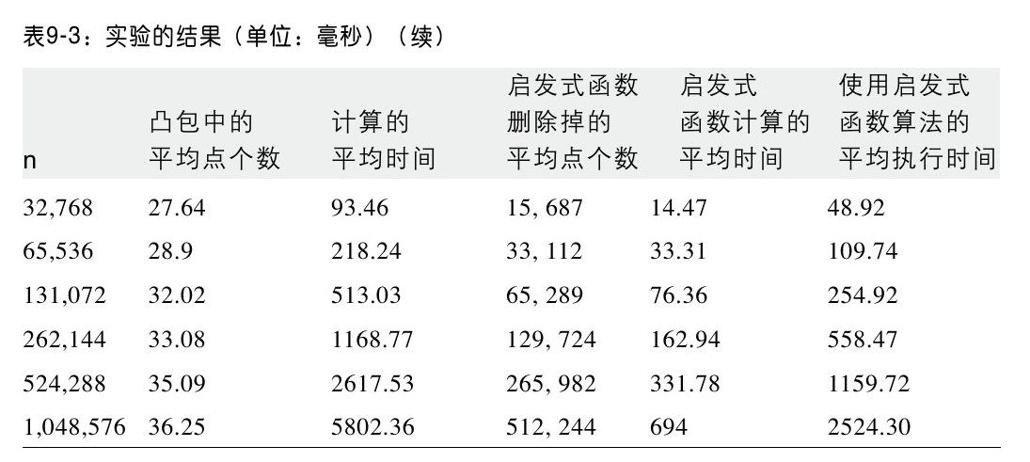
随着输入数据规模的增长,越来越多(几乎有一半)的点被启发式函数删除掉。更令人惊讶的是,规模如此之大的点集,组成的凸包的点个数却如此之少。表9-3的第2列证明了Preparata和Shamos的论断(1985):他们认为构成凸包的点个数应该为O(log n),这是非常令人吃惊的结论。如此之大的点集,组成凸包的点个数如此之少,那么每个点组成凸包的概率将会非常小。
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元
凸包扫描算法的第一步是使用标准的基于比较的排序方法,其性能开销为O(n log n)。之前我们提到过,如果输入的点本来是有序的,那么这一步可以跳过。计算上部凸包(图9-7中第4~7行)的循环需要处理n-2个点。内部的while循环(第6~7行)最多也只会执行n-2次,计算下部凸包(第9~12行)也同样如此。因此凸包扫描算法其余步骤的总时间是O(n)。
当凸包扫描算法计算叉积时,可能会出现浮点运算的误差。因此我们不会严格地判断cp<0,PartialHull采用的是计算cp<δ代替cp<0,希望能够努力消除误差,此时δ=10-9。










