预计阅读本页时间:-

随机算法
某些算法可以通过随机位序列(或者随机数)来解决问题。当假定随机访问时,我们通常能够找到解决问题的快速算法。实际上,大家应该意识到,在确定性计算当中,真正随机的序列是很难生成的。尽管我们可以生成伪随机序列,来替代真正的随机字节序列,然而生成这些随机序列的成本却是不可忽视的。
估算集合的大小
下面举个例子来说明如何利用概率算法获得计算速度的提升,假设我们要估算一个包含n个元素的集合:{x1,……,xn}的大小,也就是n的值。最直接的方法就是对所有元素进行计数。但是如果不太准确的结果也可以接受,而同时希望计算速度更快一些的话,那么下面例10-1中描述的算法会是一个更好的选择。
例10-1:概率计数算法的实现
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元

算法预期的执行时间为:
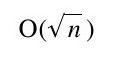
也就是说,while循环预期的执行次数为:
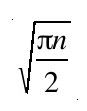
这个算法与生物学家用来估算有限空间内生物群体规模的标识再捕法很相似。显然,它不可能得到n的确切数值,因为2*k2/π不可能是个整数。但是2*k2/π是n的无偏估计,它的期望值等于n。
表10-1给出了该算法在大量独立实验组中得到的结果。概率算法产生了n的估算值的t次实验结果(t分别为32、64、128、256)。在这些实验中,最大和最小的估算结果都已去掉,每列所示的是剩下t-2次实验结果的平均值。最后三行通过计算估算值/实际值的最小比率a、最大比率b以及两者之间的差值给出了“估算平均值”的准确率。例如,32次实验中,估算值353 998相对其目标值524 288的比率最低(0.68),而1 527 380相对1 048 576的比率则最高(1.46)。
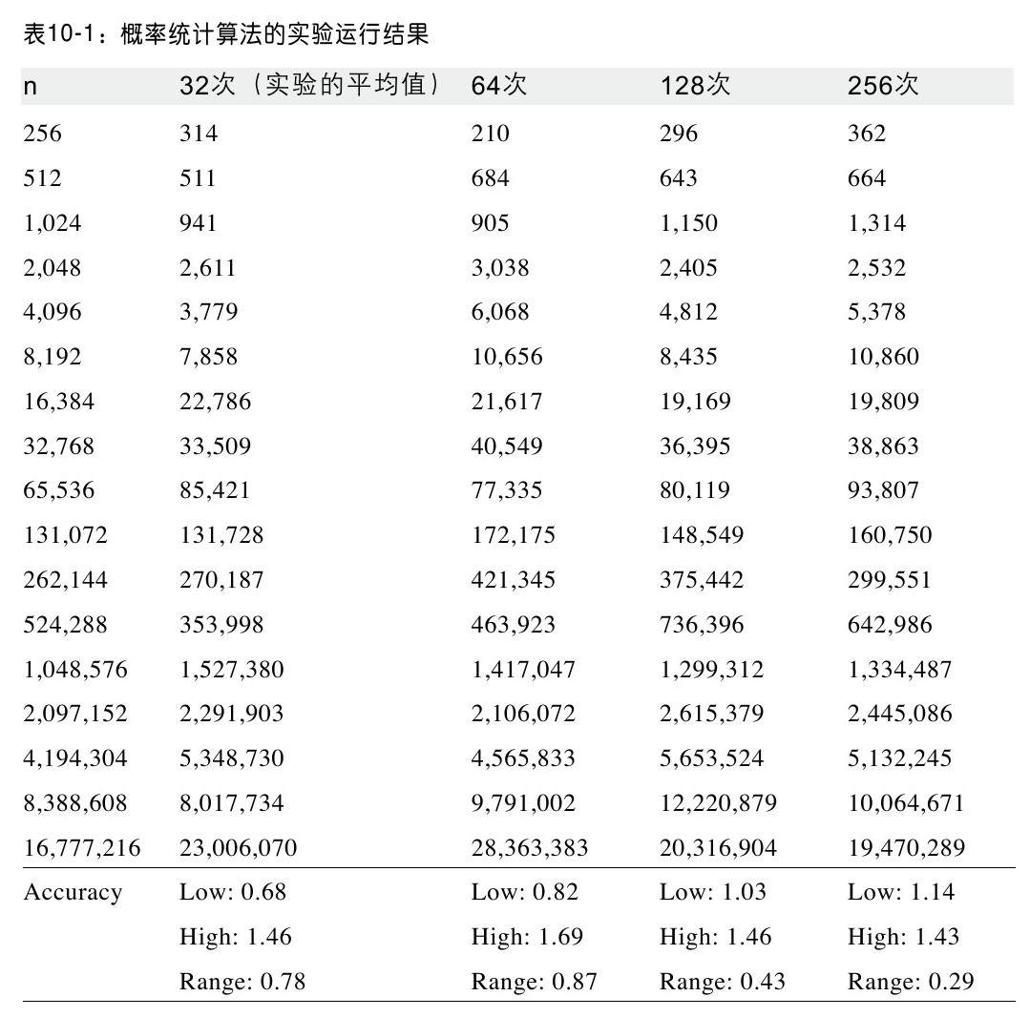
由于这次实验的随机性,所以不能完全保证可以简单的通过增加独立随机实验的次数来达到最终正确的结果。事实上,你可能需要进行非常大数量的实验才能得到想要的估算值。与其试图通过利用随机算法来获得一个确切的值,还不如去投入精力去寻找一些能够得到正确结果的算法。









