预计阅读本页时间:-

讨论3:线性算法的性能
有一些问题的解决看起来明显地需要更多的工作。任何一个8岁大的孩子都知道7+5等于12。那么难一点的问题,37+45呢?一般来说,相加两个n位的数(an……a1+bn……b1)得到一个n+1位的cn+1……c1数字有多难?相加算法使用了如下的原生操作:
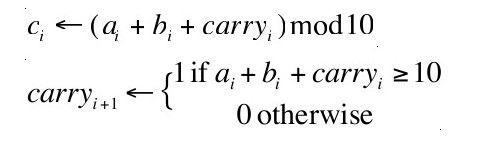
例2-2是相加算法的一个Java实现,n位数字被用一个int数组表示。在本节的例子中,我们假设数组中的元素表示一个十进制数d(0≤d≤9)。
例2-2:Java的add实现
广告:个人专属 VPN,独立 IP,无限流量,多机房切换,还可以屏蔽广告和恶意软件,每月最低仅 5 美元

只要这个输入数据能够被存储在内存中,add就能够使用两个int数组n1和n2来计算两个数的加法。例2-3有一些小改动,这个实现能够更加高效吗?
例2-3:Java的last实现

这个小改动确实影响了算法的性能吗?让我们考虑其他两个潜在因素,这两个因素将会影响算法的性能。
·编程语言是一个因素,如果这两个实现都能够转换成C程序,那么编程语言是如何影响算法的性能?
·如果这个程序能够在另外一台不同的计算机上执行,那么计算机硬件是如何影响算法性能?
这些实现将会执行10 000次,数的位数从256位到32 768位。数的每一位都是随机产生的。其后,在每次执行中,这两个数都会循环移位,产生两个不同的数进行相加。我们使用了两台计算机:桌面PC和一台高端计算机。并且使用两种不同的编程语言(C和Java)。我们一开始就假设随着数据规模的加倍,算法执行时间也会加倍。我们希望重新确认算法总体行为和计算机、编程语言以及实现无关。
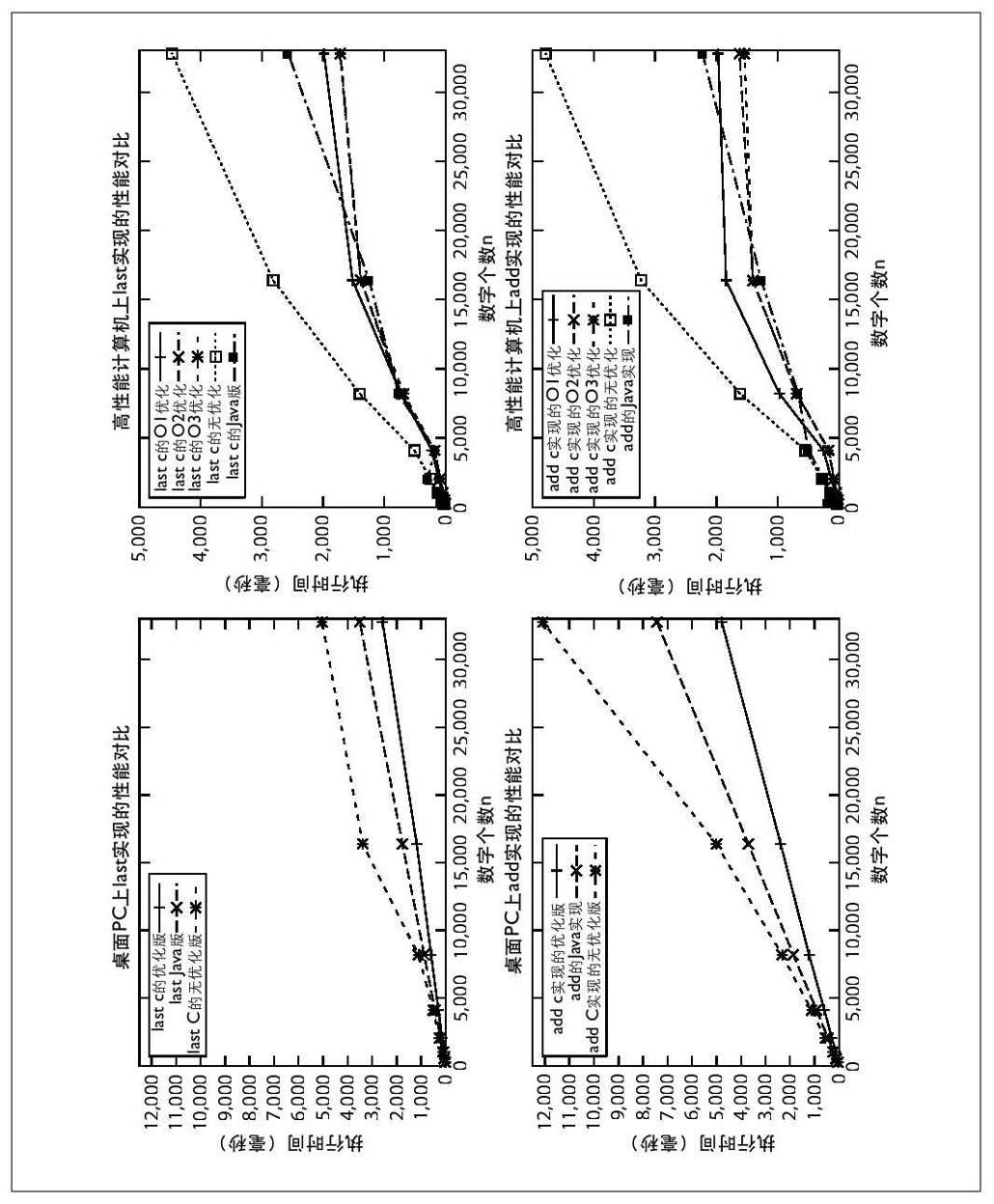
图2-5表示了数据的规模(用x轴表示)与执行10 000次(用y轴表示)的时间(单位是毫秒)的关系。每一次变化都更改了这些配置选项:
g
C程序将会把调试信息编译进去。
none
C程序不会进行任何优化。
O1,O2,O3
C程序将会按照不同的优化等级进行编译。一般来说,数字越高的意味着更好的优化与更佳的性能。
Java
算法的Java版。
PC-Java
在PC上执行,只有一种配置,之前的那些数据也同样会在高端计算机上执行。
留意在图2-5的左边(标"Desktop PC"),每条计算线的斜率都是近似线性的,这种性质表示X和Y的值之间存在线性关系。在高端计算机执行优化过的代码,计算结果却不能够简单地归为线性,因为需要考虑到高端处理器的重要影响。
表2-3包含了一些图上的数据。本书中提供的代码都会提供这种信息。表2-3的第6行、第7行和最后一行直接对比了HighEnd-C-Last-O3实现[1]在不同数据规模下的性能。性能的比率与预想的很接近,在2左右。假设t(n)是在数据规模为n的情况下,加法算法的实际运行时间。这个增长模型提供了强有力的证据,证明在高端计算机上,使用C语言并且执行O3级优化,计算n位数之和的时间将会在n/11到n/29之间。
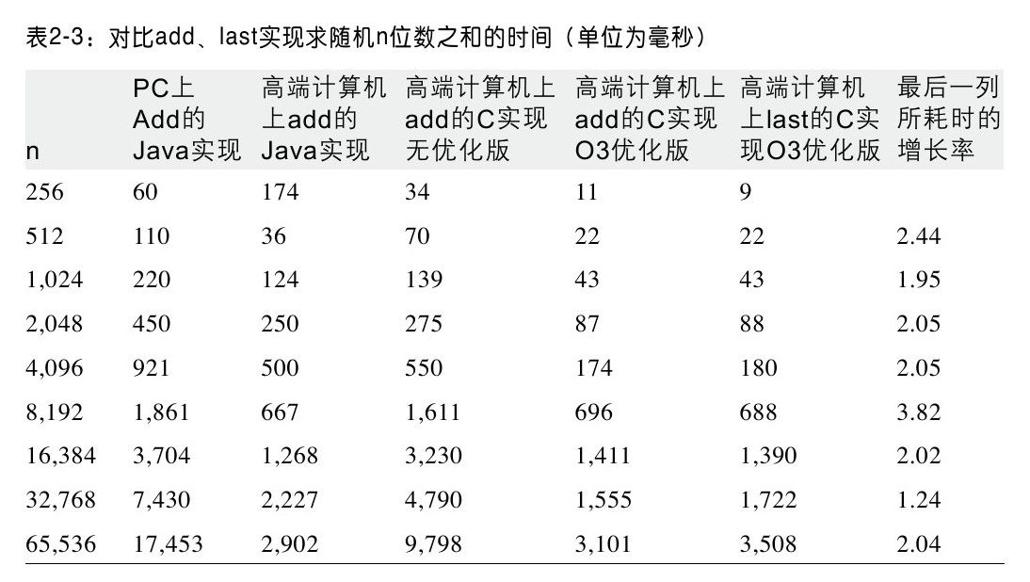
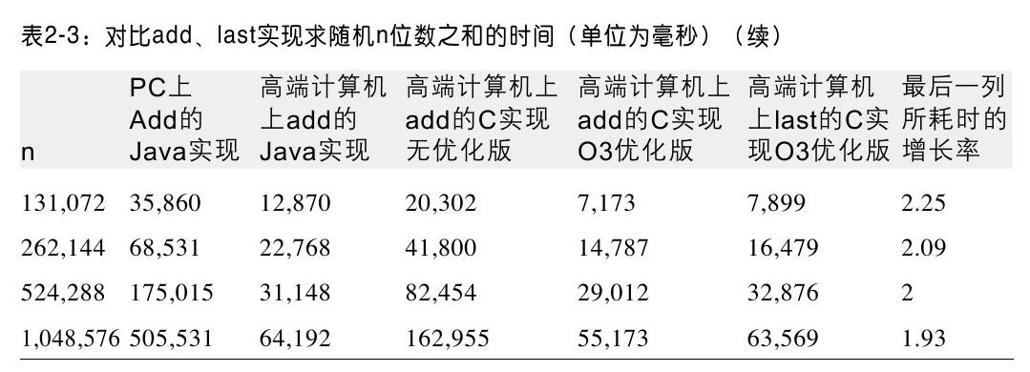
计算机科学家认为加法算法是关于输入规模呈线性的。也就是说,对于所有n>n0,存在一个常数c,c>0,使得t(n)≤c*n。事实上我们并不需要知道c或者n0的值。一个争论的焦点是,在做加法时,每一个位都必须检查(考虑一下漏掉的后果),这样的复杂程度是否需要一个线性时间下界。
在加法算法的last实现,我们设置c为1/11,选择n0为256。其他的加法实现应该会有不同的常数,但是它们的总体表现仍呈线性。这个结果让那些认为整数算术是常数操作的程序员大吃一惊。当整数的固定位数用n来表示时(例如16位或者64位),常数时间的加法是可达的。
在考虑算法间差异时,知道算法的阶数比了解常数c更为重要。看似无关紧要的差异会导致不同的性能。加法算法的last实现在不采用取模计算之后显得更加高效。在操作不是2的幂的数时,取模计算是出了名的慢。在数不能被10整除的情况下,二进制计算机做“%10”计算会有较大的开销且并不高效。当然,这并不是说我们可以忽略掉常数c的值。如果我们做大量加法的话,那么c的一点点小的变动都会对程序的性能产生很大的影响。









